appendN.cpp implements this experiment.Timer.h, and Timer.txt implement
the timer required by all experiments (there is no Timer.cpp).For this experiment, we will append n values to the end of a
container. The Perform the test step
consists of a loop that appends these n values.
We don't have to consider the cost of creating the containers because they are empty containers. It does take time to create an empty container but we can ignore it because it's constant and doesn't depend on n — it alway take the same amount of time.
Compile and run the program on the sample range of n. Enter the results into a spreadsheet and graph them.
Use the categories from Experiment #1 to categorize your results:
Question #13.3.1: How would you categorize the time it takes to append n
values to the end of a list? Justify your answer.
Question #13.3.2: How would you categorize the time it takes to append n
values to the end of a vector? Justify your answer.
Now, let's look at the two containers we're experimenting with.
listAs we saw in Experiment #2, it takes
constant time to append a value to a list. This experiment
performs that operation n times, so we might expect the running time
here to be a constant times n — i.e., linear time.
vectorNow for the other container. In
Experiment #2, we found that it takes
linear time to append a value to a vector when it is full.
If we do this n times, we end up with n*n — i.e,
n², which is quadratic time.
However, your graph probably doesn't look like it's parabolic; rather,
it's linear or close to it. What's wrong? The numbers aren't, but our
analysis is. The important phrase is "when the size and capacity
are the same." That's the situation we had in
Experiment #2. Although this does happen
here, it's very infrequent because vector does not just
increase its capacity by 1 so it can store the new value. Rather,
vector's strategy is to allocate more space than necessary
—doubling (except for some versions of C++) — assuming that more
appending of values will follow. Thus, it's much more common to have room
for the item to be appended than to be full.
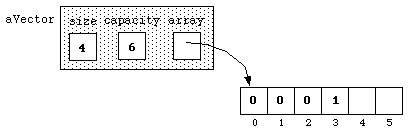
To illustrate, in our analysis in Experiment #2, we ended with this picture:
If we add another element to this vector, the vector:
aVector.That's even simpler than appending a value to a list!
Question #13.3.3: Starting with the picture above, append the values2and3to thevector. Draw two pictures, one after each append.
If you analyze things further, doubling the array when allocating a
new one (see the analysis in Experiment #2) saves us in the
long run. The size-equal-to-capacity case turns out to be quite
rare and our vector ends up using the much simpler,
constant-time case much more often.
So, on the whole, appending to a vector turns out to
appear to take constant time. Consequently, appending n
items appears to take linear time.