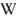 to encode your data. The encoding is
actually quite simple.
to encode your data. The encoding is
actually quite simple.Most programs do not run all of the time (except for some operating systems); you'll often want some way for your programs to save data. As the programmer, one of your first decisions is the format of the data: should you store the raw data, or should it be stored in a human-readable form?
While the code for reading and writing raw data is easy to write, it's nearly impossible for humans to read the saved data, making debugging impossible at best. A human-readable form is much easier for debugging, but the code for reading the file is much more difficult.
One way to balance these needs is to use XML
(eXtensible Markup Language) to encode your data. The encoding is
actually quite simple.
This lab will also introduce you to the Java Almanac written by Patrick Chan. While you can buy copies of this as two books, the Java Almanac is also availabled online. It contains many examples of code for Java's support libraries, including the libraries for processing XML.
The gradebook class created in Lab #9 had a lot of features in it, but there was no good way to read in the data for a gradebook. As specified in that lab, a student could have only one name; it we used a more general way to read in a name, there would have been other problems. We'd face all of these same problems (and more!) if we tried to read that same type of data from a file.
In this lab exercise, you will see how you could have used XML
to save a gradebook to be processed by your GradeBook
class.
To avoid name clashes with the classes from Lab #9 and in case that code isn't finished, we're going to use a different set of terminology: "pupils" and "pupil calculators". These two terms correspond to "student" and "gradebook" from Lab #9.
Do this...
Read the Wikipedia article on XML as linked above. The sections on
the features of XML and the quick tour should be sufficient. Know
these terms: element, tag, and
attribute. Then you'll be set to work on this
lab.
Do this...
edu.institution.username.hotj.lab10b
Design/lab10b.txt.Exercise Questions/lab10b.txt.Inputs/lab10b.quiz.xml file into
Inputs/lab10b.Do this...
Run all of the unit tests for a
green bar.
Do this...
Open quiz.xml.
You might have to persuade your IDE to do this. Try right clicking on the file and asking the IDE to open it in a text editor.
It's assumed that the quiz is worth 20 points.
Do this...
Add in data for two more pupils in the file. Make up the data.
Suppose you now wanted to compute the average score on this quiz.
First, you'll need some way to get the file name to a
PupilCalculator.
Do this...
Add a PupilCalculator constructor that receives a
String filename. This constructor should initialize
myPupils to a new ArrayList. The code
should compile, and run for a green bar.
There are several ways to process XML data. We're use two XML technologies:
The Wikipedia articles are quite dry (with hardly any examples), but they might be useful for you if you're looking for the larger context.
Your task is relatively simple (in the realm of XML processing). You can create a DOM object, a "document", quite easily from an XML file; in fact, it's hard to argue that you're doing any file I/O yourself---it's all done by the DOM library. Then, you have to probe the DOM document to get out its data. XPath is a relatively simple way to do this.
The first step is to get a Document from an XML
file.
The Java Almanac has example code for reading in an XML
file as a Document:
e510. The Quintessential Program to Create a DOM Document from an
XML File.
Do this...
Copy the parseXmlFile(String,boolean) method from
that webpage into your PupilCalculator class.
public to private.static.catch block:
throw new RuntimeException(e);
return statement at the end of the
method.PupilCalculator's
responsibility.RuntimeExceptions avoids some
bookkeeping we'd have to do if we didn't bother with the
try-catch. Throwing
RuntimeExceptions is actually a terrible way to deal
with the errors, but it's much better than what the Java
Almanac gives you!That's really it for reading XML as far as the program is
concerned. That's also it for reading in a file. The rest of your
work is with a Document.
Now, it will be helpful for you to think in terms of the XML
since the Document closely models that same structure.
The XPaths that you write will be based on this structure.
The algorithm for PupilCalculator(String) is as
follows:
Algorithm of PupilCalculator#PupilCalculator(String)
- Initialize
myPupilsto a new array list.- Let
theDocumentbe the result of parsing the XML file namedfilename.- For
ifrom 1 to the number of pupils (inclusive):
- Let
namebe the name of pupil #i.- Let
scorebe the score of pupil #i.- Let
descriptionbe the textual description of the performance of pupil #i.- Let
thePupilbe a newPupilinitialized withname,score, anddescription.- Add
thePupiltomyPupils.
So that you have a quick-reference for the data types of the variables:
Objects of PupilCalculator#PupilCalculator(String) Description Type Kind Name my pupils List<Pupil>instance variable myPupilsthe name of the file Stringparameter filenamethe DOM document Documentlocal variable theDocumentcounting index intlocal variable ithe name of the current pupil Stringlocal variable namethe score earned by the current pupil doublelocal variable scorethe description of the performance of the current pupil Stringlocal variable descriptionthe current pupil Pupillocal variable thePupil
Do this...
Implement the second statement of the
PupilCalculator(String) constructor using
parseXmlFile(String,boolean) to initialize it. Use
false for the Boolean flag.
Let's use some of this in PupilCalculatorTest.
Do this...
Uncomment the declaration of myPupilCalculator2 in
PupilCalculatorTest as well as its initialization in
setUp(). The code should compile and run for a green bar.
By using XPath, you can zero in on the parts of the document that most interest you. The Java Almanac has a webpage on XPaths. Do not worry about the Java code on that page; it's a bit outdated.
Do this...
Read over that XPath page.
You will first need an XPath to get you all of the
student nodes:
/quiz/student
This is rooted at the quiz element at the top of
the document. By itself, as an XPath, this would return a node list
of all students.
If you want to count the number of students, you can use an
XPath that passes this path to an XPatch count()
function:
count(/quiz/student)
You can use an array-like notation to access just one of these students. To get at the fifth student, you could use this XPath:
/quiz/student[5]
This should strike you odd when you compare it to array and list
processing in Java: the fifth element is at index 5?! Yes. While
most languages and libraries use zero-based indexing, XPath uses
one based indexing.
To get started, you need to access an attribute of this student.
/quiz/student[5]/@score
This will return the value of the score attribute
of the fifth student in the document.
If an element has text in it (not as an attribute), you will
want to use the text() function:
/quiz/student[5]/description/text()
...the test of the description of student #5.
Here's a helpful method for using an XPath in a DOM document to
get at a String value (instead of a node or element or
node list):
/**
* Method that retreives text data from a DOM document using an XPath.
* Non-text data can be converted with the standard parsing methods like
* {@link Integer#parseInt(String)}.
*
* @param theDocument the document where the data is located.
* @param path the XPath to the data
* @return the textual data in the document as specified by the XPath.
* @throws IllegalStateException when the XPath is incorrectly formed; this
* is <em>not</em> thrown when the data does not exist.
*/
private String getText(Document theDocument, String path) {
try {
return (String) XPathFactory.newInstance().newXPath().compile(path)
.evaluate(theDocument.getDocumentElement(),
XPathConstants.STRING);
} catch (XPathExpressionException e) {
throw new IllegalStateException("Problems with xpath " + path, e);
}
}
The XPath library has you create an XPath processor in a round-about way, without any constructors. You can see where the path is compiled and that compiled result is evaluated in the document to retrieve a string.
Do this...
Add this method to PupilCalculator. Compile your code.
Step 3 is a counting for loop. How many time does
it need to iterate? As many times as there are students in the
document.
getText(Document,String) will get that count as a
String.String to
Integer.parseInt(text),
then you'll get a count a for loop can use!Do this...
Write the control for the counting for loop of Step
3.
Steps 3a and 3b involve using
getText(Document,String) again. In the first case,
it's a matter of getting the name attribute of the
current student. In the second case, it's a matter of getting the
score attribute of that same student, and turning it
into a double. (Hint:
Double.parseDouble(.)text)
Do this...
Write the code for Steps 3a and 3b. Hint: you'll have to do some
String concatenation to get the XPath right.
Let's skip the description for now.
Do this...
Write a dummy statement for Step 3c which sets
description to the empty string.
The rest of the statements are straightforward review from previous labs.
Do this...
Implement Steps 3d and 3e.
Do this...
Uncomment the last line of code in
PupilCalculatorTest#testAverage(). Change a
??? to the correct value, and run the tests for a green bar.
Since the PupilCalculator#average() method is
correct, errors will be in your DOM-processing code.
Do this...
Add a new test method
PupilCalculatorTest#testGenerateReport(). Write an
assertion for myPupilCalculator1 which
asserts generateReport() returns an empty string.
PupilCalculator#generateReport() should return a
large string of names and scores (for now). For example, one line
will look like this:
"Sponge Bob (10/20)\n"
written here as a Java String.
Do this...
Write an assertion for myPupilCalculator2 in
PupilCalculatorTest#testGenerateReport(). The expected
value will be the concatenation of five lines like the one
above.
PupilCalculator#generateReport() is now just a
typical loop to iterate through all of the students, concatenating
together the data from each one into a master
String.
The descriptions of each student's performance is being ignored. Let's add them to the mix.
Now, instead of the one-line output for each student in the report, each student will have two lines, like so:
"Sponge Bob (10/20)\n" + "Sponge Bob should try harder on his quizzes.\n\n"
Note the two newlines after the description.
Do this...
Modify PupilCalculatorTest#testGenerateReport()
method to assert the report generated by
PupilCalculator#generateReport() with these new lines
of output. Compile your code,
and run the unit tests for a red
bar.
You can use
PupilCalculator#getText(Document,String) to get the
text from the description element of the current
student. Check the XPaths above for some hints.
Do this...
Fix the initialization of description in
PupilCalculator#PupilCalculator(String).
When you use the description to create a new Pupil,
you may want to use String#trim() to trim off the
extra whitespace at the beginning and end of the description.
Here's a silly assertion describing what String#trim()
does:
assertEquals("trimmed away the whitespace",
" \ttrimmed away the whitespace\t \n\n ".trim());
You also have to add the description to the report.
Do this...
Fix PupilCalculator#generateReport() to include the
descriptions.
Submit your code and a sample execution of your unit tets.
attribute, Document Object Model, DOM, element, eXtensible Markup Language, tag, XML