class: left, top, title-slide .title[ # Tidy Data<br>Pivoting Data ] .author[ ### Keith VanderLinden<br>Calvin University ] --- # Tidying Data with tidyr .pull-left[ `tidyr`, Tidyverse’s data structuring package, provides a *grammar* of structural manipulation “verbs” implemented as functions: - `pivot_longer()` - `pivot_wider()` - `separate()` - `unite()` As with dplyr, tidyr functions can be combined in *pipelines*. ] .pull-right[  ] ??? - This unit focuses on *tidying* data to produce the structures assumed in the previous unit (cf. the cleanse/tidy/wrangle overview in unit 5 class slide #1). - We'll focus on pivots as implemented by `pivot_longer()` and `pivot_wider()` (not `gather()` & `spread()`, covered in the RStudio tutorial but are superseded, see: https://tidyr.tidyverse.org/articles/pivot.html). --- # Dataset: Sales We’d like to work with this (fabricated) sales dataset. .pull-left[ ```r prices ``` ``` ## # A tibble: 5 × 2 ## item price ## <chr> <dbl> ## 1 avocado 0.5 ## 2 banana 0.15 ## 3 bread 1 ## 4 milk 0.8 ## 5 toilet paper 3 ``` ] .pull-right[ ```r customers ``` ``` ## # A tibble: 2 × 4 ## customer_id item_1 item_2 item_3 ## <int> <chr> <chr> <chr> ## 1 1 bread milk banana ## 2 2 milk toilet paper <NA> ``` ] .footnote[See: DataScience in a Box, https://datasciencebox.org] ??? - This dataset is a toy database with multiple tables. - Not all multi-table datasets are untidy; datasets frequently have data about single entities distributed over multiple datasets (e.g., unit 6). - The first table is tidy but the second table isn't. --- # Pivoting Datasets .pull-left[ Pivots allows us restructure a dataset to be either *wider* or *longer*. ] .pull-right[ 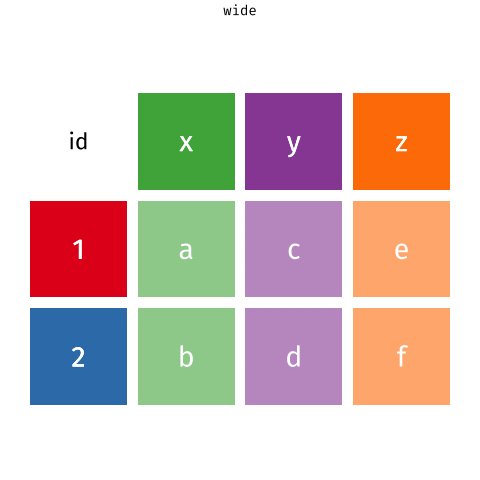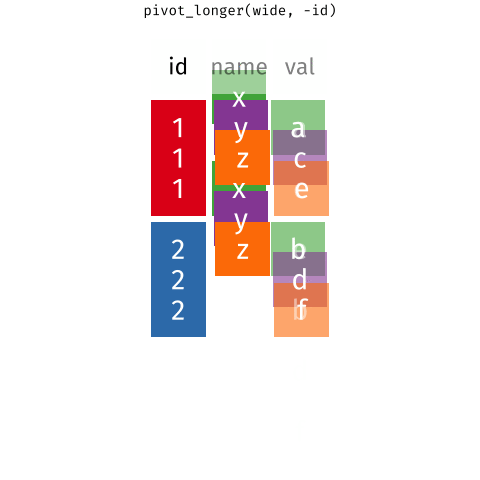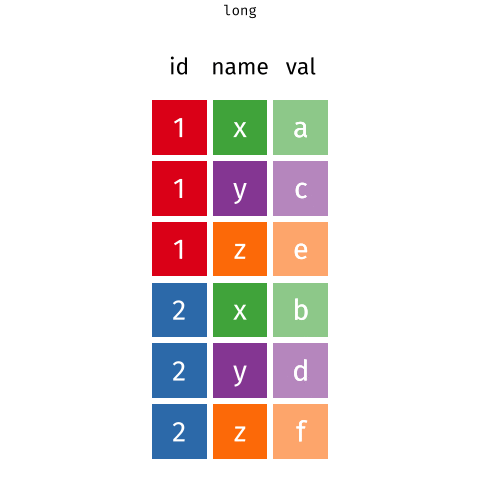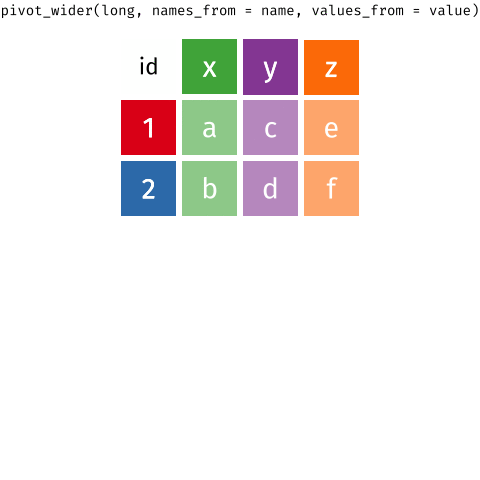 ] .footnote[Images from: TidyExplain, https://github.com/gadenbuie/tidyexplain] ??? - Briefly describe the desired output of each with respect to the sample tables. - *longer* --- Converts columns to typed rows (which is what we need for customers). - *wider* --- Converts typed rows to labeled columns. - Spreadsheets support pivots using pivot tables. --- # Pivot Longer .pull-left[ <br> <br> <br> <br> <br> ```r # The original (wide) customers table customers ``` ``` ## # A tibble: 2 × 4 ## customer_id item_1 item_2 item_3 ## <int> <chr> <chr> <chr> ## 1 1 bread milk banana ## 2 2 milk toilet paper <NA> ``` ] .pull-right[ ```r purchases <- customers %>% pivot_longer( cols = item_1:item_3, names_to = "item_num", values_to = "item" ) %>% filter(!is.na(item)) purchases ``` ``` ## # A tibble: 5 × 3 ## customer_id item_num item ## <int> <chr> <chr> ## 1 1 item_1 bread ## 2 1 item_2 milk ## 3 1 item_3 banana ## 4 2 item_1 milk ## 5 2 item_2 toilet paper ``` ] ??? - Explain the resulting table: - The `item` column contains all the names. - The item_num table includes an ordinal value, which could be useful (or not). - The result allows us to more easily add items to a single purchase. - Explain the `pivot_longer()` arguments: - `cols` - the column names to convert into type values - `names_to` - the name for the new type column - `values_to` - the values for the new rows --- # Pivot Wider .pull-left[ <br> <br> ```r # The new (long) purchases table purchases ``` ``` ## # A tibble: 5 × 3 ## customer_id item_num item ## <int> <chr> <chr> ## 1 1 item_1 bread ## 2 1 item_2 milk ## 3 1 item_3 banana ## 4 2 item_1 milk ## 5 2 item_2 toilet paper ``` ] .pull-right[ ```r purchases %>% pivot_wider( names_from = item_num, values_from = item ) ``` ``` ## # A tibble: 2 × 4 ## customer_id item_1 item_2 item_3 ## <int> <chr> <chr> <chr> ## 1 1 bread milk banana ## 2 2 milk toilet paper <NA> ``` ] ??? - This just reverses the previous pivot. - Explain the `pivot_wider()` arguments: - `names_from` - the columns into which to put the values - `values_from` - The values to put there --- # The Value of Wide vs. Long Structures .pull-left[ The wide format doesn’t allow us to join in price data and it forces us to add columns for additional item purchases. ```r # The original (wide) customers order table customers ``` ``` ## # A tibble: 2 × 4 ## customer_id item_1 item_2 item_3 ## <int> <chr> <chr> <chr> ## 1 1 bread milk banana ## 2 2 milk toilet paper <NA> ``` ] .pull-right[ The long format allows us to add purchases by adding rows and to join data from the prices table for each purchase. ```r purchases %>% left_join(prices) ``` ``` ## Joining, by = "item" ``` ``` ## # A tibble: 5 × 4 ## customer_id item_num item price ## <int> <chr> <chr> <dbl> ## 1 1 item_1 bread 1 ## 2 1 item_2 milk 0.8 ## 3 1 item_3 banana 0.15 ## 4 2 item_1 milk 0.8 ## 5 2 item_2 toilet paper 3 ``` ] ??? - The wide format is not tidy. - The long format is tidy!