Build a spam filter based on Paul Graham’s A Plan for Spam. You’ll find a sketch of his statistical algorithm early in the article (roughly one-fifth of the way through the article).
Include in your solution, as one test case, the probability tables for the words in the following hard-coded SPAM/HAM corpus (and only this corpus) using a minimum count threshold of 1 (rather than the 5 used in the algorithm):
spam_corpus = [["I", "am", "spam", "spam", "I", "am"], ["I", "do", "not", "like", "that", "spamiam"]] ham_corpus = [["do", "i", "like", "green", "eggs", "and", "ham"], ["i", "do"]]
Graham argues that this is a Baysian approach to SPAM. What makes it Bayesian?
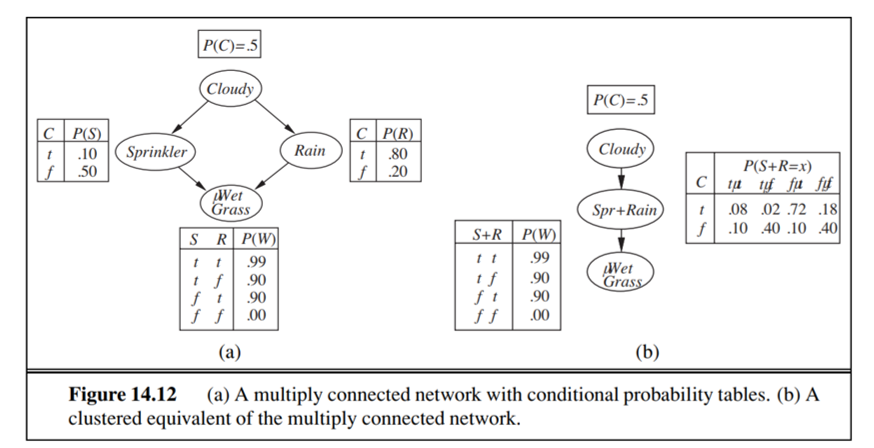
Do the following exercises based on the Bayesian network shown in Figure 14.12a:
Provide both computer-generated solutions and hand-worked derivations of how these numbers are computed.
Submit a Jupyter notebook (homework2.ipynb).
We will grade your work according to the following criteria:
See the policies page for homework due-dates and times.
{kind=link}