NLP Tasks
With your neighbors, discuss the following questions about the conditional distribution to the right.
Part A: Which of the following statements are true?
- The model will generate this joke 25.71% of the time.
- The model will generate a
WhyafterTell me a joke\n\nQ:25.71% of the time. - The model is 25.71% confident that this is a joke.
- The model would assign a score of 68% to
Tell me a joke\n\nQ: What don't scientists trust atoms?\nA: They make up everything.
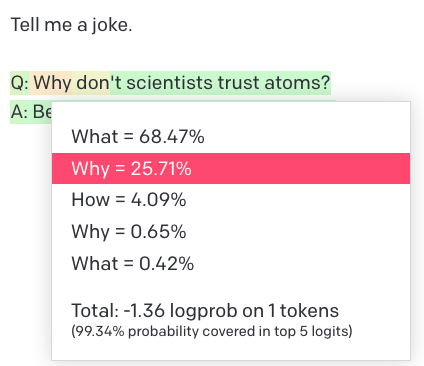
Part B: Was the Temperature slider set at 0 or at 1? How can you tell?
Part C: Where does “-1.36 logprob” come from?