Welcome Survey
- “I learn way better through struggling and hands on practice than through lecture”
- 3 Nathan, 2 Caleb, 2 Ben
- Range of background: help each other. Piazza
Logistics
- Homework 1: Check your submission. You may need to resubmit.
- Homework 2 posted.
- Python Warm-up Quiz: Review the solutions.
- Weekly reflection
Review
Unit 1 objectives
- Identify some of the major milestones in the history of AI.
- Contrast contemporary ML-based and numerical AI with classical rule-based and symbolic AI
- Describe how modern machine learning uses data to learn parameters for a program
- Implement basic numerical computing operations using PyTorch
- Implement a simple image classifier on a pre-wrangled dataset using fast.ai.
Unit 2 objectives
- Describe the structure of data fed to an image classifier
- Contrast a training set and validation set; explain appropriate uses of both
- Write Python code to prepare a dataset for an image classifier.
- Identify ethical issues pertaining to the collection and use of data in AI systems
- Implement multidimensional numerical computing operations using PyTorch
Lab 1 Walkthrough with Q&A
(done live)
Q&A
Overfitting as a problem?
The figure in the book is misleading.
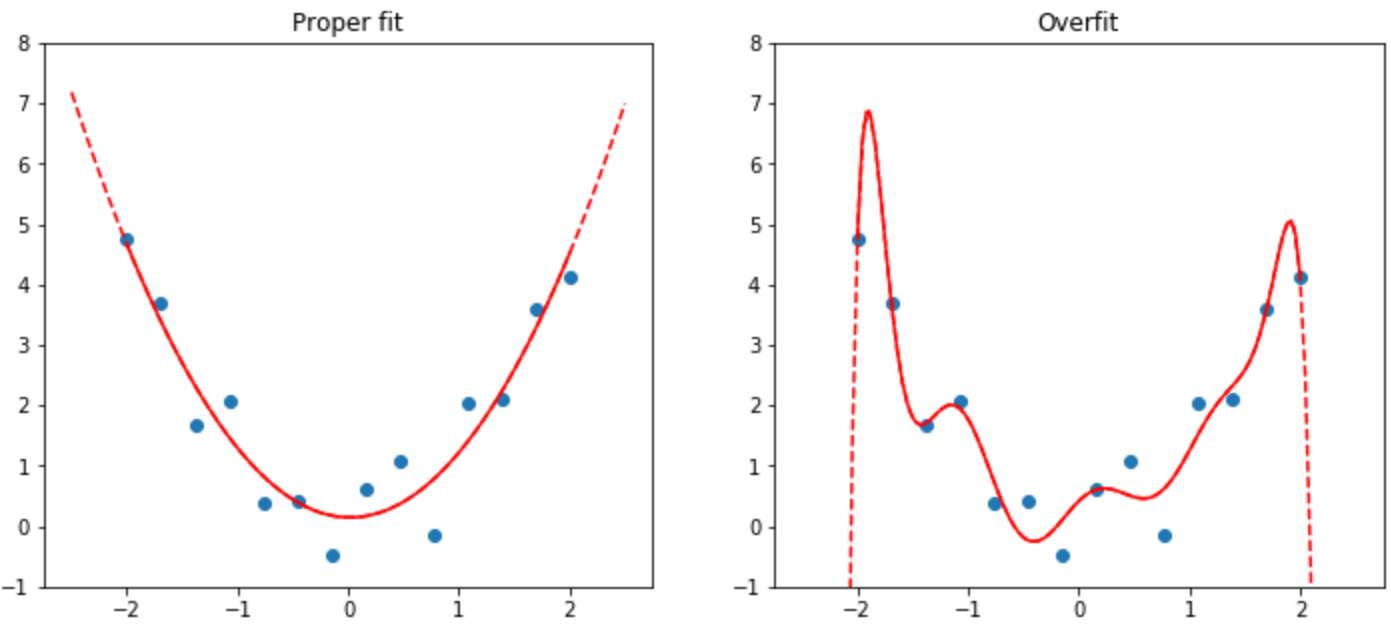
- That’s a polynomial fit. It’s much more sensitive than the functions typically used in NN’s.
- Recent results: a model can completely memorize its training set while still generalizing well (its behavior away from training set points is typically much better behaved than the figure suggests!), and in fact continue to improve generalization performance after reaching 100% accuracy (e.g., Grokking paper).
- Early stopping might hurt because of “double descent”.
- So yes, overfitting can be a problem, but don’t angst over it, just keep training.
- But: memorization might be a problem. “Phone: xxx-yyy-zzzz. SSN: "
There’s also underfitting. Underfitting means that the model isn’t capturing the patterns even of the training data. It usually means that your model is too small (so the range of functions it can approximate isn’t rich enough), or your training is insufficient (your learning rate is too low, you’re not giving it enough time to train, there’s something broken about the training process, etc.).
Why Python?
- Many libraries: talk with databases, webservers, IoT, GUIs, etc.
- Particularly good scientific computing ecosystem (NumPy, SciPy)
- Readable!
- Flexible: Enough metaprogramming to be concise where needed; some limited amount of magic is possible.
- Fast enough. Core operations are in low-level code; Python is the conductor.
- Array programming
- Benefits of GPU: highly parallel. Good for array operations (matrix multiply, nonlinearity, softmax)
- Computer graphics often requires doing nearly the same sequence of operations to lots of polygons and ending up with lots of pixels. Analogously, machine learning often requires doing nearly the same sequence of operations to lots of numbers. So hardware that was designed to do graphics well has been repurposed to do machine learning well too.
- GPU hardware has been adapted to be better suited for machine learning too, e.g., the addition of tensor cores.
Lots of jargon!
The more often something shows up in class, the more important it is to know.
Do we need math?
Yes! But not all at once. Some highlights:
- Linear algebra: vectors, linear operators (matrix multiplication), dimensionality reduction
- Calculus: chain rule
Can we explore the validation set, or should we leave it totally hidden?
To get some assurance about how our model will work once deployed, we need some data that we intentionally don’t look at until the very end. That’s the test set. But we often need to guess at how well it’s going to work before then—e.g., because we’re adjusting a parameter that might affect how well the model generalizes. The validation set (or, sometimes, validation sets) help us estimate that.
In general, it’s a good idea to look at the validation set to understand how and why the model worked or didn’t, e.g., get an overview of what kinds of images an image classifier tends to misclassify. But it’s probably not a good idea to study it in too much depth, or it will stop being a good proxy for the test set.
What if the randomly selected held-out part was the most unhelpful?
(Note: validation of 20% means training set is 80%.)
- This is why we need sizeable validation sets. (What if it happened to pick only the easiest examples for validation?)
- Randomness usually helps: it’s pretty unlikely to randomly select all extreme examples
- But do audit your choices, especially when summary stats may hide issues, e.g., unusually poor performance for a minority.
What are layers? What does each one do?
Gradually integrating information from wider area of the image. Lower layers = really zoomed in.
Converting sound to image is a cool idea.
Recently this approach has been replaced by: turn everything into a sequence and pretend it’s language.
Pretrained models are useful.
But can introduce bias, may not actually be as helpful as thought (more later).
How might we prove the universal approximation theorem?
- Specific theorems vary, but generally: any two linear transforms with a nonlinearity in between can approximate an arbitrary function.
- Intuitively, think about representing a single-variable function by piecewise lines (that’s basically a ReLU approximation, as we’ll study.)
- More generally, you can approximate any function by gradually refining a mesh and interpolating between the points.
- Beyond that, see the Wikipedia page and citations there.
How to collect data?
- Lots of preexisting datasets
- Logs from your website, app, IoT
- Crowdsource labels
AI libraries?
- PyTorch vs TensorFlow: very similar; historically Tensorflow more industry and PyTorch more research but that’s less clear now
- Keras, fast.ai, PyTorch Lightning: high-level libraries for making common patterns fast in TensorFlow and PyTorch
- newcomer: JAX. Simple automatic differentiation layer (autograd) on top of hardware-accelerated linear algebra primitives (XLA). Google.
Epoch?
One full pass through the training data. Not uncommon to see tens or hundreds of epochs, depending on training set size.
SGD?
- Gradient descent: which little wiggle would improve performance on the whole dataset?
- SGD: which would improve performance on these few images I just saw?
- SGD gets to a better solution faster than complete gradient descent. (intuition: more chances to try something and get feedback.)