
list Class TemplateWe have seen that the vector class provides one means of
storing a sequence of values provided by the Standard Template
Library (STL). The STL also provides another container for storing
sequences of values called a list. With the exception of
operator[], at(), capacity(), and reserve(), any of the operations that can be applied to a vector can also be applied to a list. If the two containers
are this similar, what is the difference between them?
This lab's exercise is to explore the differences between these two containers, to understand how they differ, and to identify the circumstances under which each should be used. This exercise consists of five timing experiments to time how long it takes to do each of five different operations on either structure:
list or vector.list or vector of
length n.list or
vector.list or vector of length n.list
or vector.Directory: lab14
Timer.h and Timer.doc implement
the timer required by all experiments (there is no Timer.cpp).Timer class.list and vectorvectorConsider this declaration:
vector<int> aVector(3);This defines
aVector as an object capable of storing three
int values, and it initializes each element to zero (the
default int value). We can visualize such an object like so:
One key property of a vector is that the elements of a vector
are allocated in adjacent memory locations. That is, in the
computer's memory, aVector[0] is physically next to aVector[1], which is physically next to aVector[2], and so
on.
listNow consider this declaration:
list<int> aList(3);This preallocates a sequence of linked nodes, consisting of a header node and three additional nodes, linked together with pointers. We can visualize these nodes like so:
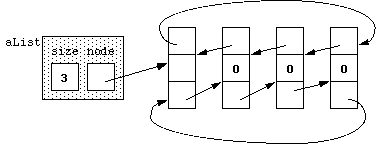
A pointer is a special kind of variable that can store the physical address of
an object. Each node in a list contains two pointers: the
first pointer points to the next node in the sequence, and the second
points to the previous node in the sequence. You see these pointers
as arrows in the picture above.
Since they are connected using pointers, the nodes in a list
need not be in adjacent memory locations; they can be anywhere
in a program's free store of memory---and they usually are! By
following the pointers, we can get from aList to the header node, the node at the
head of the list without any data in it. The header node is
just there to provide a starting node for the next and previous
pointers. From the next-node pointer of the header node we can get
to the first node of the list; from the next-node pointer of
the first node we can get to the second node of the list; and
so on. We can go the opposite way through the list following
the previous-node pointers. A list's nodes can be scattered
throughout memory and the order of the values in the list is
determined solely by the next-node and previous-node pointers of the
nodes.
Because the elements of a vector are stored in adjacent
memory locations, the subscript operation can be performed
efficiently for a vector. The expression aVector[i]
is a simple arithmetic computation:
aVector.array + (i * sizeof(int))In contrast, trying to access the element #i of a
list would require that we start at the header node and follow its
next-node pointer to node #0; follow the next-node pointer of node #0
to node #1; follow the next-node pointer of node #1 to node #2; and
so on until we reach node #i. This requires a loop, and
computation for each pointer we follow---more time consuming that the
vector's simple math computation. Consequently, a list does not have an subscript operator.
Timer ClassTo measure the elapsed time in each experiment, we have provided a
Timer class stored in the file Timer.h. This class
computes time in seconds like a stopwatch timer, and can be
manipulated via the following operations:
| Statement | Meaning |
|---|---|
Timer aTimer; |
Constructs aTimer as a Timer object. |
aTimer.start(); |
Starts aTimer running. |
aTimer.stop(); |
stops aTimer. |
aTimer.reset(); |
Resets aTimer to zero. |
cout << aTimer; |
Displays the elapsed time recorded by aTimer. |
aTimer.getSeconds() |
Returns the current value of aTimer. |
The Timer class is built using the clock() function
from ctime, an ANSI C library; it should be portable to any
platform that supports ANSI C. This also means that the Timer class is only as accurate as the underlying clock()
function.
Most of the operations that we test in this exercise are very, very fast. So fast, that the program probably will not notice them running at all because the timer cannot measure fractional seconds very well. So, instead of timing just one run of each test, the programs run each test many, many times----1000 times, by default. (Tweak this number if the tests take extra ordinarily long on your machine.) The program computes the average of all iterations by dividing the total elapsed time by the number of iterations.
The driver for each experiment follows this algorithm:
n.list using n.vector using n.list and for a vector.n changes from experiment
to experiment.
Regardless of what container is being tested and the exact test, the algorithms for the tests themselves follow the same structure:
ITERATIONS times:
Perform the test.Perform the test" step is the only difference from
program to program in testing the different operations.
For each experiment, we recommend running the programs on n set to the values 100 through 2000 (inclusive) in increments of 100 (e.g., 100, 200, 300, ..., 1800, 1900, 2000). We will call this the sample range of n. Your instructor may have an alternative sample range depending on the particulars of the computer and compiler that you use.
Experiment #1: Creating New Containers
Experiment #2: Appending One Value to a Container of Size n
Experiment #3: Appending n Values to an Empty Container
Experiment #4: Prepending One Value to a Container of Size n
Experiment #5: Prepending n Values to an Empty Container
list or vectorYou won't be able to answer this question until you've gone through all of the experiments.
Question #14.1: Using the results from the five experiments and your knowledge ofvectors andlists, under what circumstances would you use one container or the other? Consider these issues:
- The operations that they provide.
- The time categories for the various operations. A constant-time operation is preferred over a linear-time operation which is preferred over a quadratic-time operation.
Turn in the answers to the questions posed in this lab exercise as well as your graphs of the running times.