
In past exercises, we have dealt with sequences of values by processing the
values one at a time. Now we want to examine a new kind of object
called a vector that can store not
just one value, but an entire sequence of values. Like a string, a vector is a subscripted object, meaning the values within it can be accessed via
a subscript or index:
The components or "spaces" within a vector in which values can be
stored are called the vector's elements. Unlike strings which only store chars,
vectors can be used to store any type of data.
By storing a sequence of values in a vector, we can design operations for the sequence, and then implement such operations in a function that receives the entire sequence through a vector parameter.
Vectors are implemented for us in C++ as the vector class in
the vector library which is part of the C++ Standard Template Library (STL). The
STL contains many containers and algorithms that are useful in many
different situations. We'll only explore a very small portion of the
STL in this lab.
This lab's exercise is to write a program that processes the names and scores of students in a course, and assigns letter grades (A, B, C, D or F) based on those scores, curving the grades. The format of the input file is a series of lines, each having the form:
namescore
As usual, we will use object-centered design to design our solution.
Directory: lab10
DoubleVectorOps.h, DoubleVectorOps.cpp, and DoubleVectorOps.doc
implement various operations for vectors of doubles.grades.cpp implements a skeleton driver.scores1.data, scores2.data,
and scores3.data are sample input files.Makefile is a makefile.gcc users need a makefile; all others
should create a project and add all of the .cpp files to
it.
Add your name, date, and purpose to the opening documentation of the code and documentation files; if you're modifying and adding to the code written by someone else, add your data as part of the file's modification history.
Begin by editing the file grades.cpp, and take a few moments
to look it over. As indicated by its documentation, grades.cpp is a skeleton program that (partially) encodes an
algorithm to solve the problem. This lab's exercise will involve
completing this program.
Up until now, our programs have been able to fully process their input as soon as it was read in. This is actually quite rare. Often, as in this lab's problem, we need to keep our information around for a long time.
Let's start at the end product: to assign a letter grade, we need to know the student's score. That's fine: read in the score, and print the corresponding letter grade. However, how can we assign the letter grade? We first need to know the average and standard deviation of all of the scores; the only way to know this is to sum all of the scores, and then we can compute the average and standard deviation.
Consequently, the scores have to be processed twice: once to figure out the average and standard deviation; a second time to assign letter grades based on the average and standard deviation.
We could use a file to store the sequence, and then reread the file each time we need to process the values. The problem with this approach is that reading from a file is very, very, very slow compared to reading from main memory---a thousand times as slow!
A much better solution is to use an internal container, in this
case, a vector. In addition to being much faster than
input from a file, a vector gives us immediate access to any
element stored in the vector.
Our program should display a greeting, and then prompt for and read the name of an input file. It should then read a sequence of names and a sequence of scores from the input file. It should then compute the average and standard deviation of the sequence of scores, and display these values. Using the average and standard deviation, it should compute the sequence of letter grades that correspond to the sequence of scores. It should then display each student's name, score and letter grade.
When we examine our behavioral description for objects, we find these objects:
| Description | Type | Kind | Name |
|---|---|---|---|
| a greeting | string | literal | -- |
| The name of the input file | string | varying | inFileName |
| a sequence of names | vector<string> | varying | nameVec |
| a sequence of scores | vector<double> | varying | scoreVec |
| the average score | double | varying | average |
| the standard deviation of the scores | double | varying | stdDeviation |
| a sequence of letter grades | vector<char> | varying | gradeVec |
We can thus specify the behavior of our program this way:
Specification:input (keyboard): the name of an input file.
input (input file): a sequence of names and scores.
output (screen): the average and standard deviation of the scores, plus the sequences of names and scores, and the sequence of corresponding letter grades.
From our behavioral description, we have these operations:
| Description | Predefined? | Name | Library |
|---|---|---|---|
Display a string | yes | << | iostream |
Read a string | yes | >> | iostream |
| Read a sequence of names and scores from a file | no | -- | -- |
| Compute the average of a sequence scores | no | -- | -- |
| Compute the standard deviation of a sequence scores | no | -- | -- |
| Compute the sequence of letter grades corresponding to a sequence scores | no | -- | -- |
| Display sequences of names, scores and letter grades | no | -- | -- |
There are several undefined operations, so it appears we'll be writing quite a few functions for this lab.
We can organize the preceding objects and operations into the following algorithm:
nameVec and scoreVec with values from
the input file.scoreVec.gradeVec, a vector of the letter grades
corresponding to the scores in scoreVec.nameVec, scoreVec and
gradeVec.vector objects: nameVec storing string values, scoreVec storing
double values, and gradeVec storing char
values.
vector ObjectsVectors are declared like so in C++:
vector<Type>vecObj;
This declaration defines vecObj as a vector
containing values of type Type.
A programmer using a vector must specify the type of value
they want to store in a given vector. While a vector
is generally useful for storing any type of data, we
always know exactly what type of data we want to put in given a
particular problem. While we could try to keep track of the
particular type ourselves, it's much, much better to let the compiler
worry about it.
The vector class is known as a template class; that is, it's be templated
to allow us to specify the Type of data that is stored in
each vector.. A complete discussion of templates and
template classes is beyond us at this point, but for now it suffices
to know why and how to use them.
With the vector class template, the compiler will check
everything done with vecObj. Only Type
objects can be put into vecObj; only Type
objects will come out. No one (neither the programmer nor the
compiler) is ever surprised by the contents of a vector.
In grade.cpp, use this information to define the three
vectors needed in the main program: nameVec, scoreVec, and gradeVec. The first two vectors are declared
early in the function; gradeVec is declared later. (The
comments tell you where.) Each of these vectors stores a different
type of data so write the declarations with this in mind. Also make
sure you include the vector library.
vector Objects from a FileNow let's start tackling the undefined operations in our main
algorithm. The first undefined operation is to read in names and
scores from a file. The name of the file is in inFileName; the names and scores should be placed into the vectors that you just declared in the main program.
We'll call this function fillVectors().
We can describe how this function should behave as follows:
Our function should receive the name of an input file, an emptyvectorof strings and an emptyvectorof doubles from its caller. The function should open anifstreamto the input file. It should then read each name and score from theifstream, appending them to thevectorof strings and thevectorof doubles, respectively. When no values remain to be read, our function should close theifstream, and pass back the filledvectorobjects.
Using the behavioral description, our function needs the following objects:
| Description | Type | Kind | Movement | Name |
|---|---|---|---|---|
| The name of the input file | const string & | constant | in | inFileName |
An empty vector of strings | vector<string> & | varying | in & out | nameVec |
An empty vector of doubles | vector<double> & | varying | in & out | scoreVec |
a stream to inFileName | ifstream | varying | local | inStream |
| a student's name | string | varying | local | name |
| a student's score | double | varying | local | score |
Given these objects, we can specify the behavior of our function as follows:
Specification:receive:inFileName, astring;nameVec, avector<string>; andscoreVec, avector<double>.
passback:nameVecandscoreVec, filled with the values frominFileName.
Since this function seems unlikely to be generally reuseable, we will
define it within the same file as our main function. Using the above
information, place a prototype for fillVectors() before the
main function, and a function stub after the main function.
Since inFileName is a class object that is received but
not passed back, it should be defined as a constant reference
parameter, not as a value parameter. In contrast, nameVec
and scoreVec are passed back, and so should be defined as
reference parameters.
In our behavioral description, we have the following operations:
| Description | Predefined? | Name | Library |
|---|---|---|---|
Receive inFileName, nameVec and scoreVec | yes | function call mechanism | built-in |
Open an ifstream to inFileName | yes | ifstream declaration | fstream |
Read a string from an ifstream | yes | >> | fstream |
Read a double from an ifstream | yes | >> | fstream |
Append a string to a vector<string> | yes | push_back() | vector |
Append a double to a vector<double> | yes | push_back() | vector |
| Repeat reading and appending for whole file | yes | eof-controlled input loop | built-in |
Close an ifstream | yes | close() | fstream |
Pass back vector objects | yes | reference parameter | built-in |
We can organize these objects and operations into the following algorithm:
inFileName, nameVec and scoreVec.inStream, a stream to inFileName, and
check that it opened successfully.name and score from inStream.name to nameVec.score to scoreVec.inStream.To append values to a vector, use the vector
method named push_back():
vectorObject.push_back(newValue);
Such a statement "pushes" newValue onto the back of the
vector named vectorObject.
Using this information, complete the stub of fillVectors().
Then compile what you have written and make sure that it is free of
syntax errors before proceeding.
The next undefined operation should average the scores. An important
observation here is that it doesn't matter that the values are
scores. They could be temperatures, heights, weights, times, or
any double values. So the average() function
that we'll write computes the average of some generic double
values, regardless of what they actually mean.
It's important to note this now because it will have an effect on the
way we name our variables. Yes, we'll continue to think of the
scores as scores in the main program (and other functions), but in
average() we'll think of them as just a sequence of real
numbers.
We can describe how this function should behave as follows:
Our function should receive avectorofdoublevalues. It should add up the values in thevector, and if there is at least one value in thevector, our function should return the average of the values (i.e., the sum divided by the number of values). Otherwise, our function should display an error message and return a default value (e.g., 0.0).
Using the behavioral description, our function needs the following objects:
| Description | Type | Kind | Movement | Name |
|---|---|---|---|---|
A vector of doubles | const vector<double> & | varying | in | numVec |
the sum of the values in the vector | double | varying | local | sum |
the number of values in the vector | int | varying | local | numValues |
| an error message | string | literal | local | -- |
| a default return value | double | literal | local | 0.0 |
Given these objects, we can specify the behavior of our function as follows:
Specification:receive:numVec, avector<double>.
precondition:numVecis not empty.
return: the average of the values innumVec.
Since we've designed this function to be generally reusable, we will
define it within a library named DoubleVectorOps.
Place a prototype for average() in DoubleVectorOps.h
and DoubleVectorOps.doc, and a function stub in DoubleVectorOps.cpp.
Since numVec is a class object that is received but not
passed back, it should be defined as a constant reference parameter.
In our behavioral description, we have the following operations:
| Description | Predefined? | Name | Library |
|---|---|---|---|
Receive numVec | yes | function call mechanism | built-in |
Sum the values in a vector<double> | yes | accumulate() | numeric |
Determine the number of values in a vector<double> | yes | size() | vector |
Divide two double values | yes | / | built-in |
Return a double value | yes | return | built-in |
| Display an error message | yes | << | iostream |
| Select between normal case and error case | yes | if statement | built-in |
We can organize these objects and operations into the following algorithm:
numVec.sum, the sum of the values in numVec.numValues, the number of values in numVec.numValues > 0:
sum / numValues.cerr.As noted above, the STL contains not only containers (like vector), but it also contains algorithms. The function accumulate() is one such algorithm, and it comes from the library
named numeric. This function adds up the values in a vector:
accumulate(vectorObject.begin(),vectorObject.end(), 0.0)
This expression returns the sum of the values in vectorObject. To use accumulate(), you must include the
numeric library in your program.
Another operation we need is to determine the number of values in a
vector. This is considerably easier:
vectorObject.size()This expression evaluates to the number of values in vectorObject. The size method is part of the vector
class, and so you must include the vector library (which must
be done anyone so that you can declare vectorObject in the
first place).
Using this information, complete the stub for average().
Then uncomment the call to average() in the main function,
translate and test your program. Don't forget to include the numeric library! Verify that your program is correctly computing
the average of the values in the input file before you proceed.
vector and the Standard Template LibraryIn writing the average() function, we used of one of the
vector methods, size(); and we used one of the C++
standard library algorithms, accumulate(). Being
knowledgeable about what methods and algorithms can be applied to an
object is important because it allows you to avoid reinventing the
wheel. We could have written our own functions to find the
number of values in a vector, or add up the values in a
vector, but why go to all that extra effort when we can use
the provided one? Learning about the functions and algorithms that
can be applied to an object takes time, but it is time well-spent,
since it provides ready-made solutions for many of the problems you
will encounter.
As mentioned earlier, vector is our first look at a template
class. The vector template is just one of many different
kinds of containers provided by the C++ Standard Template Library.
Other containers include the list, the set, the
map, the stack, the queue and a variety of
others. Each of these containers has its own unique properties that
distinquish it from the others. These containers are typically the
subject of later computer science courses, and so we will not discuss
them further here.
Some of the vector methods and each of the STL algorithms
make use of a new kind of object called an iterator. An iterator is an object that can move
through a sequence of values and access each of the values in turn.
Each of the containers in STL provide iterators for processing their
elements, and each of the STL algorithms take a container's iterators
as arguments, which they use to access the elements in that
container.
It is through iterators that the STL algorithms can be written easily
to handle any of the STL containers. Otherwise, the authors of
the STL would have to write an accumulate() function for every container implemented in the STL. In fact, we could write our
own, brand-new container (perhaps never seen before in the history of
computing); as long as we wrote iterators for our new container, we
could use all of the STL algorithms without having to change the code
for those algorithms.
A complete discussion of iterators is beyond us at this point;
however, it is useful to understand that each of the containers
(including vector) contains a method begin() that
returns an iterator to its first element, plus a method end()
that returns an iterator pointing beyond its final element.
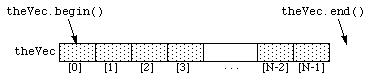
These two iterators thus mark the beginning and end of a container.
An STL algorithm (like accumulate()) can then use these two
end points of the container to iterate through the whole container
and do its work (e.g., add the elements together).
Returning to our problem at hand, we next need to write function to
compute the standard deviation of our scores. standardDev()
will be given a vector of double values, and it will
return the standard deviation of those values.
Since a proper discussion of standard deviation would take us into statistics, we'll black box the computation. That is, the specification and algorithm are given below without the rest of the OCD design. Generally you do want a good understanding of the problem you're working on and of the solution you come up with for the problem. But in some cases, one person may design a solution, and some one else may be asked to implement it.
The specification for this function is as follows:
Specification:receive:numVec, avector<double>.
precondition:numVecis not empty.
return: The standard deviation of the values innumVec.
Since this function is generally reusable (just like average()), it should also be defined in our DoubleVectorOps library.
Using this specification, place a prototype for standardDev()
in DoubleVectorOps.h and DoubleVectorOps.doc, and a
function stub in DoubleVectorOps.cpp.
As before, numVec should be defined as a constant
reference parameter.
An algorithm to compute the standard deviation is as follows:
numVec.numValues, the number of values in numVec.numValues > 0:
avg, a double initialized to the
average of the values in numVec.sumSqrTerms, a double initialized to
zero.i of numVec:
term, a double initialized to
numVeci - avg.term2 to sumSqrTerms.sumSqrTerms / numValues).cerr.We use the notation numVeci to refer to
the value in numVec whose index is i.
Vector size. To determine the number of values in a vector, we can use the size() method, as before.
Average. To compute the average of the values in a vector, we can use the average() function that we just
defined.
The loop. The loop can be implemented as a counting for loop that counts from 0 to numValues minus one:
for (int i = 0; i < numValues; i++) ...
This is perhaps one of the most common ways to process a vector. Become very familiar with this loop since you will see it
in any program that uses a vector. It's a little different
from the counting loops we've used in the past; the primary reason
for this is because vector indices start at index 0.
Element access. To access a value from a vector,
the subscript operation can be applied to the vector, in the
same manner as a string. The pattern is:
vectorObject[index]
This expression evaluates to the value that is stored within
vectorObject at index index.
Do it. Using this information, complete the stub for
standardDev(). Then uncomment the call to standardDev() in the main function, and translate and test what you
have written.
You should get the following standard deviations (approximately):
| File | Standard Deviation |
|---|---|
scores1.data | 11.1803 |
scores2.data | 2.69186 |
scores3.data | 0.927025 |
Print a hard copy of each of the three scores files. Take a moment and and look over the distribution of scores in each file.
Question #10.1: If you were assigning grades, what letter grades would you assign for the scores inscores1.data,scores2.dataandscores3.data? Assume the scores are out of a possible 100 points. Write your letter grades on the printouts.
Our current task is to write a function that computes the appropriate letter grades for the input scores, curving the grades as appropriate. This function needs a sequence of scores to process, and it must return a corresponding sequence of letter grades; we can specify what the function must do as follows:
Specification:receive:scoreVec, avectorofdoublevalues.
return:gradeVec, avectorofcharvalues.
Since this function seems pretty tightly tied to this particular
grading problem, we will define it locally, within grades.cpp.
Using this information, prototype computeLetterGrades()
before the main function and define a stub following the main
function. Since scoreVec is a class object that is
received but not passed back, define it as a constant reference
parameter.
There are various ways to curve the grades based on a collection of scores. We'll base it on the average and standard deviation of the scores:
Here is the algorithm:
scoreVec, a vector of scores.numValues, the number of values in the vector.gradeVec, a vector of characters the same
length as scoreVec.numValues > 0:
avg, the average of the values.standardDev, the standard deviation of the values.F_CUT_OFF as avg - 1.5 * standardDev.D_CUT_OFF as avg - 0.5 * standardDev.C_CUT_OFF as avg + 0.5 * standardDev.B_CUT_OFF as avg + 1.5 * standardDev.i of scoreVec:
scoreVeci < F_CUT_OFF:
gradeVeci to 'F'.scoreVeci < D_CUT_OFF:
gradeVeci to 'D'.scoreVeci < C_CUT_OFF:
gradeVeci to 'C'.scoreVeci < B_CUT_OFF:
gradeVeci to 'B'.gradeVeci to 'A'.gradeVec.Using the information above, complete the definition of computeLetterGrades(). Then compile what you have written to check
for syntax errors.
The final operation is to display the information we have computed.
Design and write a function that, given an ostream, a vector of names, a vector of scores, and a vector of
letter grades, displays these three vector objects in tabular
form. For example, the output produced when scores1.data is
processed should appear something like the following:
Enter the name of the scores file: scores1.data Mean score: 75 Std. Dev: 11.1803 joan 55 F joe 60 D jane 60 D jim 65 D janet 70 C john 70 C johanna 75 C jack 75 C joeline 75 C jacques 75 C josh 80 C janna 80 C jason 85 B jadzia 90 B jon 90 B jackie 95 A
If you find that you have logic errors in what you have written, use the debugger to find them.
Question #10.2: Whenscores2.dataorscores3.dataare processed using our curve, how do the curved grades compare with the grades you assigned?
Question #10.3: What have you learned about grading on the curve?
Turn in your answers to the questions in this exercise, a copy of your code, and a sample run of the program on at least the three provided data files.