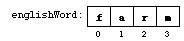
There are many problems that involve processing and analyzing text in much the same way as analyzing sentences in a natural language such as English to find nouns, verbs, adjectives, adverbs, etc. and determining if they fit together according to the grammar rules of that language.
string data type.
string type
provided in the C++ string library. Some of the problems
in the programming projects prepared for this lab exercise require using
similar string operations in some simple data encryption methods. The
textbook (C++ for Engineering and Science) describes,
in addition to C++'s string class, its
istream and ostream classes and
complex class for processing complex numbers. It also describes
a RandomInt class for generating random numbers that are
useful in programming simulations.
Making a noun plural usually consists of adding an 's', but sometimes there are special cases. Consider these examples:
Singular noun Plural noun exercise exercises noun nouns word words abscess abscesses summons summonses box boxes hobby hobbies party parties
As for Pig Latin, there are two basic rules:
(NOTE: Vowels are 'a', 'e', 'i', 'o', 'u', and 'y' (unless it begins the word). Words in which 'u' is the first vowel and it is preceded by 'q' also require special treatment as described later.)
English Pig Latin English Pig Latin alphabet alphabetyay nerd erdnay billygoat illygoatbay orthodox orthodoxyay crazy azycray prickly icklypray dripping ippingdray quasimodo asimodoquay eligible eligibleyay rhythm ythmrhay farm armfay spry yspray ghost ostghay three eethray happy appyhay ugly uglyyay illegal illegalyay vigilant igilantvay jury uryjay wretched etchedwray killjoy illjoykay xerxes erxesxay limit imitlay yellow ellowyay messy essymay zippy ippyzay
stringops.cpp is a
program for you to use to try out some string operations described in the
first part of this lab exercise.
==>
in the opening documentation.
==> at the beginning of main().
The file translate.cpp is a
driver for translating keyboard input from English to Pig Latin. Later in
this lab exercise you will repeat the preceding 3 steps for it and then add
a function englishToPigLatin() to it, inserting its prototype
and definition at the designated places of the program.
For both problems — pluralizing nouns and english-to-pig-latin
conversion — we begin by studying C++'s string type
that is provided by the <string> library. Note the
compiler directive
#include <string>
in the translate.cpp program.
The string data type in C++ is implemented with a
class. The main difference between a class such as
string and simple types such as
int and double is that a class
encapsulates both data and actions together in
one object (as opposed to the simple types, which must be "shipped off" to
other functions that perform the required actions). In a future lab, we'll
look at how to build our own classes, but for now we'll restrict our
attention to those provided in C++.
A string object is used to hold a sequence (i.e., string)
of characters. A single character (i.e., a char) isn't, in
general, as useful as strings; so you'll probably find yourself using
strings almost every time you need to process text.
string ObjectsWe can easily declare and initialize string objects with
string literals; for example,
After the declaration,string englishWord = "farm";
englishWord is a string
object tnat contains the string of characters that make up the word
farm.
A string is an indexed type, which means that
we can access individual characters in the string by specifying their
positions:
englishWord and can be used to access the
individual characters within it.
One important thing about indexing the characters of a string is where the indexing starts:
Remember: The indexing of a stringalways starts at 0.
So the first character of the string has index 0, the second
character has index 1, the third character has index 2, and so on up
to the last character whose index is one less than the size of
the string. Keep this in mind as you use indices to
access the characters and substrings of a string.
string OperationsAs mentioned above, a class encapsulates both data and actions into
one object. As a class, the string class provides many
operations that can be performed on string objects.
Operations in a class are usually implemented as
member functions (also known as methods
or instance methods), which are simply functions
provided within that class. In a later lab we will
see how to make these definitions ourselves, but for now all we need
to know is how to call them. This requires a slightly different syntax for
a function call:
Up to now, we haven't attached an object name to the function name when
we called a function. However, to call (or "invoke") a member function
inside an object, we must specify the object to which it is to be applied.
And this is done by attaching the object's name to the member function with
the dot operator.
object.memberFunctionName(arguments);
Member functions can be thought of as messages
sent to an object and the dot (.) as a "push-button"
operation that sends the message (somewhat like buttons on a stop watch
or a calculator or a phone and so on). For example,
We can think ofint size = stringObject.size();
stringObject receiving a message
size() that asks it to figure out and report back
its size. In other words, "Hey, stringObject,
what's your size?" This metaphor becomes more
important when we implement classes, but it's also helpful in
mastering this new syntax for calling methods.
Let's look at a few of the operations provided by the string
class. In the following table, str is of
type string:
Description Syntax Explanation Index operator str[index]Returns the character at position indexinstr. Ifindexis out of range forstr, it will return a "garbage value" or cause the program to crash.Size of a stringstr.size()Returns the size of the string str.Concatenation of two stringsstr1+str2Returns the stringformed by attachingstr2at the end ofstr1.Equality of two stringsstr1==str2Returns trueif the twostrings are equal,falseotherwise.Substrings str.substr(start,size);Returns the substring of strconsisting of thesizecharacters starting at indexstart.Finding characters in a string. str.find_first_of(pattern,index)Returns the index of the first character in patternfound instr, starting at positionindex. If no matching character is found,string::nposis returned.
The first four operations are quite straightforward. The following statements illusrate how they are used:
Now let's look at some examples of thestring str = "milesperhour"; cout << str << endl; cout << str[0] << str[1] << str[2] << str[3] << str[4] << endl; cout << "Size = " << str.size() << endl; cout << str + " (mph)" << endl; if (str == "MilesPerHour") cout << "Yes\n"; else cout << "No\n";Question #7.1: What output will be produced by these statements? Predict what you think will be produced and then enter the statements in
stringops.cppand execute it to check your answers.
substr() method:
string sub1 = str.substr(0,5); cout << sub1 << endl; sub1 = str.substr(5,3); cout << sub1 << endl; sub1 = str.substr(8,0); cout << sub1 << endl; sub1 = str.substr( 0, str.size() ); cout << sub1 << endl;Question #7.2: What output will be produced by these statements? Predict what you think will be produced and then enter the statements in
stringops.cppand execute it to check your answers.
In these examples, it is important to note that the second argument is a size, not an index (a common mistake).
The find_first_of() method is a little more complicated, but
is very useful. Consider this code:
string factorial= "n! = 1 * 2 * ... * n";
int firstIndex = factorial.find_first_of(".*!?", 0);
TheQuestion #7.3: What output will be produced by these statements? Predict what you think will be produced and then enter the statements in
stringops.cppand execute it to check your answers.
find_first_of() method searches factorial
to find the first occurrence of a character from the pattern
".*!?". It does not need to
find the entire pattern, just one of the characters from the
pattern. So, in the code above, firstIndex will be
set to the index of the first exclamation mark in the string.
Starting a search at the beginning of a string — i.e., at position 0
— is common but isn't required. We can start the search anywhere within
the string. To illustrate, suppose we wish to continue the search in the
preceding example beyond the first occurence of the first .,
*, or !. We need only conduct a search starting
with the character after the one we found in the first search :
int secondIndex = factorial.find_first_of(".*!?", firstIndex + 1);
This starts the search right after the previous search and finds the
second occurrence of one of the characters.
Question #7.4: What will be the value of secondIndex?
Question #7.5: What would be the value ofsecondIndexif we started the search atfirstIndexinstead offirstIndex + 1?
Memorizing a complete description of a library such as
string is usually not necessary; in fact, in most cases it
isn't really feasible. What is important is to know generally
what's available in the library, where you can find the library, and
most importantly, where you can find documentation for the library —
for example, in your textbook (perhaps in an appendix) or by searching the
Internet.
Here is a handy string Library Quick Reference that describes some of the most useful string operations. Don't try to memorize them, but be able to come back to this section when working with these string operations. It might be wise to print this quick reference and keep a hard copy (or a pdf file) handy.
After examining the table of examples of singular and plural nouns at the beginning of this exercise, we can formulate some simple rules:
Here's how our function should behave:
Our function should receive a singular noun.
If the noun ends in "s" or "x", return the noun with "es" attached at the end.
Otherwise, if the noun ends in "y", return the noun with the "y" replaced with "ies".
Otherwise, return the noun with "s" tacked on the end.
Here are the objects we need:
Description Type Kind Movement Name the singular noun stringvariable in singularNounthe index of the last character of the noun intvariable local lastCharIndexthe last character of the noun charvariable local lastCharthe plural noun stringvariable out --
And we can write a specification for our function:
Specification:Up to now, we've usedreceive: a singular noun, astring
precondition: the noun should be singular
return: the plural version of the noun, astring
assert() or an if statement
to check preconditions. Trying that here would require
a lot of work because there is no easy way to tell whether a
word is a noun and, in addition, whether it is singular.
In such situations when it isn't practical to enforce preconditions in our code, we settle for indicating clearly to those using the function that this is a precondition. If someone uses our function with a plural word (like "nouns") and gets strange results (like "nounses"), that's not our problem because we warned them!
Using the string operations listed above and other operations
we've seen before, here are the operations we need for this function:
Description Predefined? Name Library receive a value yes parameter built-in if...otherwise... yes ifstatementbuilt-in get last character of string yes []andsize()stringcompare characters yes ==built-in concatenate two strings yes +stringextract a substring yes substr()stringreturn a string yes returnbuilt-in
And here is our algorithm:
singularNoun.lastCharIndex be the size of singularNoun minus 1.lastChar be the character of singularNoun at index lastCharIndex.lastChar is 's' or 'x',
singularNoun + "es".lastChar is 'y',
base be singularNoun without the
trailing "y".base + "ies".singularNoun + "s".Let's turn now to coding the Pig Latin translator.
Like the pluralizer, the Pig Latin translator will have certain rules for transforming words that are based on the contents of the word. In the case of the pluralizer, the rule we used was determined by the last letter of the word. For the Pig Latin translator, it will be the location of the first vowel.
Let's look at some examples:
The main point in both rules is the first vowel. In additon to 'a', 'e', 'i', 'o', and 'u', we will treat 'y' as a vowel except when it is the first letter of the word. For example, "my" becomes "ymay" in Pig Latin, but "your" becomes "ouryay."
Here's a first attempt at our our Pig Latin translator is to behave:
Receive an English word. Find the position of the first vowel in that word, checking that a vowel was actually present. If the word begins with a vowel other than 'y', then return the concatenation of the English word and "yay". Otherwise, the Pig Latin word consists of three parts(in order): (1) the portion of the English word from the first vowel to its end, (2) the initial consonants of the English word, and (3) "ay". Return the Pig Latin word.
Here are the objects that we need:
Description Type Kind Movement Name the English word stringvariable in englishWordindex of the first vowel intvariable local vowelPositionthe Pig Latin word code string variable out piglatinWordportion of the English word from its first vowel to its end stringvariable local lastPartconsonants at the beginning of the English word stringvariable local firstPart"yay" stringconstant local -- "ay" stringconstant local --
This gives the following specification for our function:
Specification:Receive:englishWord, astring.
Precondition:englishWordshould be an English word.
Return:piglatinWord, astring.
Use the specification to create a prototype for a function named
englishToPigLatin(). The rest of the design is up to you
— identifying the operations needed and developing an algorithm.
As with the noun-pluralizing function, checking the precondition isn't really
feasible. The driver program (translate.cpp) where you will
put your function prompts the user to enter English sentences, so you need
not be concerned about what happens if they don't.
Task: Begin work on your Pig Latin translator function by identifying the operations needed and developing an algorithm for it. Even if you aren't required to hand it in, it will help a lot if you write some of this down and have it handy as you begin to work on the function definition.
We can code our algorithm for the "pluralizing" algorithm as follows::
string pluralize(string singularNoun)
{
int lastCharIndex = singularNoun.size() - 1;
char lastChar = singularNoun[lastCharIndex];
if ((lastChar == 's') || (lastChar == 'x'))
return singularNoun + "es";
else if (lastChar == 'y')
{
string base = singularNoun.substr(0, lastCharIndex);
return base + "ies";
}
else
return singularNoun + "s";
}
Now let's break this down and spend some time comparing it with the algorithm.
The first statement in the pluralize function,
Step 1: Receive singularNoun.
This is done automatically through the parameter passing mechanism.
Step 2: Let lastCharIndex be the size of
singularNoun minus 1.
The first statement in the pluralize function,
int lastCharIndex = singularNoun.size() - 1;
uses the size() method to get the index of the last character.
Step 3: Let lastChar be the character of
singularNoun at index lastCharIndex.
The second statement in the pluralize function,
char lastChar = singularNoun[lastCharIndex];
uses this index to get the last character of
singularNoun.
Step 4:
If lastChar is 's' or 'x'
Return singularNoun + "es"
Otherwise if lastChar is 'y'
(a) Let base be singularNoun without the trailing "y"
(b) Return base + "ies"
Otherwise,
Return singularNoun + "s"
is implemented by the multi-branch if statement
at the end of the function:
if ((lastChar == 's') || (lastChar == 'x'))
return singularNoun + "es";
else if (lastChar == 'y')
{
string base = singularNoun.substr(0, lastCharIndex);
return base + "ies";
}
else
return singularNoun + "s";
Each of the conditions in the if statements compares
two chars and determines which rule to apply.
Each rule results in a string concatenation, the first and last of which
are quite simple; but the second one requires a closer examination.
Recall that the substr() method needs an index where it is
to start extracting a substring and the length of the substring to be
extracted. The beginning index is easy: because we want everything but the
last character (which is a 'y' we're discarding), we need to start at
index 0. It doesn't matter what's in singularNoun or
how long it is — a string always begins at index 0.
But how long is this substring? lastCharIndex is the
index of the last character — the character we need to avoid. Because
the indices of the individual characters begin with 0, the index of any
one character is equal to the number of characters that precede it. For
example, for the string "play", the indices of the
characters are 0, 1, 2, and 3, so the last character (y) has
index 3, and there are 3 characters that precede it.
This explains why lastCharIndex is doing double duty
as an index into singularNoun and as a size
for the substring.
Now, go back and compare Step 4 of the algorithm with the code,
noting how straightforward each step of the algorithm translates
into code. You may struggle some with the syntax of the code since this
is your first look at the string operations being used. The double use of
lastCharIndex is a bit tricky, but otherwise the algorithm
and the code match up very well.
The trickiest operation is finding the first vowel in a word.
Unlike the noun pluralizer, you cannot simply test a fixed position with
the index operator. Rather, you have to search for it.
However, take another careful look at the table of string
operations given earlier and the examples that follow it. One of those
methods is exactly what you need!
Then, after locating the first vowel, you need only extract the
appropriate substrings from the English word and use the concatenate operator
(+) to build up the Pig Latin word to be returned by the
function.
Test your Pig Latin translator on all of the words from the table of examples given earlier and others that you want to try (and perhaps some others that your instructor assigns.)
As you test your function, you'll discover that your function doesn't work on all words; in particular, words that begin with 'y' or that contain a 'q' in the initial consonants.
Words beginning with 'y' pose a problem because we've been considering 'y' to be a vowel. If we didn't, words like "style" or "spry" wouldn't translate properly. However, for most words that begin with 'y' such as "yellow" and "yard", the initial 'y' should be treated as a consonant so that the Pig Latin versionis are ""ellowyay" and ""ardyay."
Note: Your program won't be perfect, however, because for some words, such as "Ypsilanti" and "yperite", the initial 'y' acts as a vowel. But we won't worry about these!Question #7.6: Add code to your function to handle this special case of words beginning with 'y' and test it with the words "yellow" and "yard".
Words with a 'q' in the initial consonants followed by a 'u' also pose a problem because the 'u' after the 'q' should also be moved to the end of the word. For example, "squire" should translate to "iresquay", not "uiresqay". This requires a special case.
We can complicate the special case further if we permit English words that do not have a 'u' after a 'q'. Strictly speaking, this isn't permitted in English, but many foreign words absorbed into English have a 'q' without a 'u' right after it; for example, the country "Qatar."
These two cases should be considered for a full-fledged Pig Latin translator and your instructor may wish to assign them. (See Project 6.1.) There are also some other interesting string-processing projects, including two that deal with encryption and decryption.