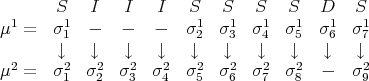
We will refer to any member of the set {A, C, G, T, -} as a character and to any subset an alphabet. Throughout this paper σ denotes a sequence over the alphabet {A, C, G, T}. Sequences can be expanded by inserting the character at - anywhere in the sequence. This includes inserting - at the very beginning and at the very end. Expanded sequences are denoted by μ.
As an example, given the sequence ACCTGAC, the following are expanded sequences by inserting the character -: A - CCTGAC, and -ACCTGAC.
An alignment of two sequences σ1 and σ2 is to expand them by inclusion of - so that the expanded sequences are of same length and are in 1-1 correspondence. We will momentarily precisely define this notion, but first let us look at an example. Let σ1 = ACTGT and σ2 = CACCCG be two sequences. Let μ1 = -ACT - GT, and μ2 = CACCCG- be the corresponding expanded sequences. Now μ1 and μ2 can be put in 1-1 correspondence:
hence, we have aligned the two sequences.
Definition 1.1. A substitution, denoted by S, is an assignment of a character from the set {A, C, G, T }to a character of the set {A, C, G, T }, i.e., it is an ordered pair in {A, C, G, T }×{A, C, G, T }.
Thus, for example, in the previous correspondence μ1 ↔ μ2, the second, third, fourth, and sixth assignments (read from left to right) are substitutions, the fourth substitution is a mismatch; others are identities.
Definition 1.2. An insertion, denoted by I, is an assignment -→{A, C, G, T }, i.e, an ordered pair in {-}×{A, C, G, T }.
Thus, for example, in μ1 ↔ μ2, the first and fifth assignments are insertions.
Definition 1.3. A deletion, denoted by D, is an assignment of a character from {A, C, G, T }to -, i.e, an ordered pair in {A, C, G, T }×{-}.
Thus, for example, the seventh assignment in μ1 ↔ μ2, is a deletion.
Each edit string induce two expansions of a given sequence. One, literally an insertion operation, is to insert the character - where an I is found in the string. In order to execute all the edits and edit every member of the original sequence, the length of the sequence must be the sum of the number of S and the number of D in the edit sequence.
The other is a deletion operation formed by inserting - where a D is found (It is rather ironic that deletion operation is formed to expand a sequence, but note the name was used simply because D are used in someway to expand the sequence). In this case we tacitly assume that the sum of number of S and number of I in the edit string is length of the original sequence.
Now we are ready to define an alignment precisely.
Definition 1.5. An alignment of an ordered pair of sequences (σ1, σ2) is an edit string that induces an insertion expansion μ1 on σ1 and a deletion expansion μ2 on σ2 such that μ1 is in one-to-one correspondence with μ2.
Let n and m be the lengths of σ1 and σ2. From the discussion preceding the definition, it is clear that an edit string is an alignment iff

Example 1.1. Let σ1 = ACGTAGC and σ2 = ACCGAGACC. Then the edit string SSISISSIDS is an alignment of σ1 and σ2 because

Alignment of sequences can be made into a problem of determining paths in directed graphs.
Definition 2.1. The alignment graph  n,m is the directed graph on the set of nodes
{0, 1, …, n}×{0, 1, …, m}and three classes of directed edges horizontal, vertical, and
diagonal defined below:
n,m is the directed graph on the set of nodes
{0, 1, …, n}×{0, 1, …, m}and three classes of directed edges horizontal, vertical, and
diagonal defined below:
2.1. Identification of sequences on the graph.
To align two sequences σ1 and σ2 of length n and m, the left most edges of the
zeroth column of n,m are identified with the terms of the sequence σ1, i.e.,
σ11 ↔ [(0, 0) → (1, 0)], …σ
n1 ↔ [(n - 1, 0) → (n, 0)]. Likewise, the m directed edges of
the zeroth row of n,m are identified with the elements of σ2. Notice we go with rows and
columns rather than x and y coordinates.
2.2. Interpretation of S, I, and D on the graph. Insertions I are interpreted as the directed horizontal edges, more precisely, [(i, j) → (i, j + 1)], 1 ≤ i ≤ n - 1, 0 ≤ j ≤ m - 1 is the insertion of - between the ith and i + 1 characters of the first sequence σ1. That - corresponds to σj2 which was earlier identified with the edge [(0, j), (0,j + 1)]. Segments [(0, j) → (i, j + 1)], 0 ≤ j ≤ m- 1 are the insertions - at the very beginning of σ1 and assigning that to σj2. Similarly interpret the insertions along the very lower edges.
Deletions D are interpreted as directed vertical segments. More precisely, the directed vertical edge [(i, j) → (i + 1, j)], 0 ≤ i ≤ n - 1, 0 ≤ j ≤ m is the assignment of σi+11 (which was identified with the segment [(i, 0), (i + 1, 0)]) to -.
Directed diagonals [(i, j) → (i + 1, j + 1)], 1 ≤ i ≤ n, 1 ≤ j ≤ m are substitutions S. Thus the substitution [(i, j) → (i + 1, j + 1)], 0 ≤ i ≤ n - 1, 0 ≤ j ≤ m - 1 means the assignment σi+11 → σ j+12.
Thus every edit string corresponds to a unique path from (0, 0 ) to (n, m) and conversely. In other words aligning two sequences is equivalent to determining a (continuous) path from (0, 0) to (n, m).
An immediate consequence of the identification is the following recurrence relation.
Corollary 2.1. Let an,m, n ≥ 1, m ≥ 1 be the total number of paths from (0, 0) to (n, m). Then

and we have set an,-1 = 0 and a-1,m = 0.
The proof is obvious once we look at the 3 nodes in n,m from which (n, m) can be
reached.
2.3. Weighted paths. As a means of distinguishing paths, we now assign weights to the edges of the graph, that is, a weight is assigned for each substitution, insertion, or deletion. The insertion [(i, j) → (i, j + 1)] is assigned the weight w(-, σj+12). The deletion [(i, j) → (i + 1, j)] is assigned the weight w(σi+11, -). The substitution [(i- 1, j - 1) → (i, j)] is assigned the weight w(σi1, σ j2). These weight matrices are given, below; the (5, 5) entry is left blank since a correspondence insertion to deletion (-, -) is, of course, not used. The weight of a path is the total weight of edge of the path and it is viewed as the cost of the path.
Example 2.2. The following illustrate the path corresponding to the edit sequence SSISISSIDS and the weights of the first few edges.


The weight of the edit string (path) SSISISSIDS applied to σ1 and σ2 in example (1.1)
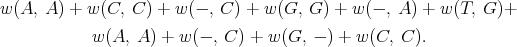 |
The weights described can be put in the form of the weight matrix.
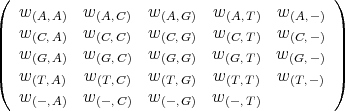
For simplicity, the diagonal entries are taken as zero. All deletions and insertions will be given the same weight. Thus the all fifth column entries and 5th row entries are the same. Finally all mismatch substitutions will have the same weight.
The algorithm provides the path(s) of minimal cost to reach all points on the graph from (0, 0).
The concept of the algorithm is that given a path of total minimal weight, the minimal weight path to any point on the graph is the sub path of the path reaching the point.
The weight of any path lying wholly on the top row (zeroth row) is the sum of weights of the horizontal segments of the graph. The only path that can reach a point on the top row has to lie wholly on the top row. Similarly for the vertical path lying wholly on the left most column (zeroth column).
Now consider the three paths that can reach (1, 1): S, ID, or DI. Pick the path with minimal (total) weight and color it in blue. Now consider the point (1, 2). It can be reach from and only from (1, 1), (0, 1), or ( 0, 2). The minimal weight path all those 3 points is now known. Hence obtain the minimal path to (1, 2) and color it blue. Continuing in this manner we will have the minimal path to every point.
Now we will formally write the algorithm. Here M(i, j) is the total weight of along the minimal path of reaching i the row jth column position. First initialize the algorithm by defining M(0, 0) = 0. Then M(0, j) = M(0, j - 1) + w(-, σj2), 1 ≤ j ≤ m and M(i, 0) = M(i - 1, 0) + w(σi1, -), 1 ≤ i ≤ n.
The loop: for 1 ≤ i ≤ n, 1 ≤ j ≤ m
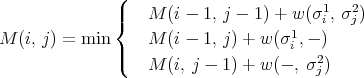
The backtrack: Trace the blue optimal path from (n, m) to (0, 0).