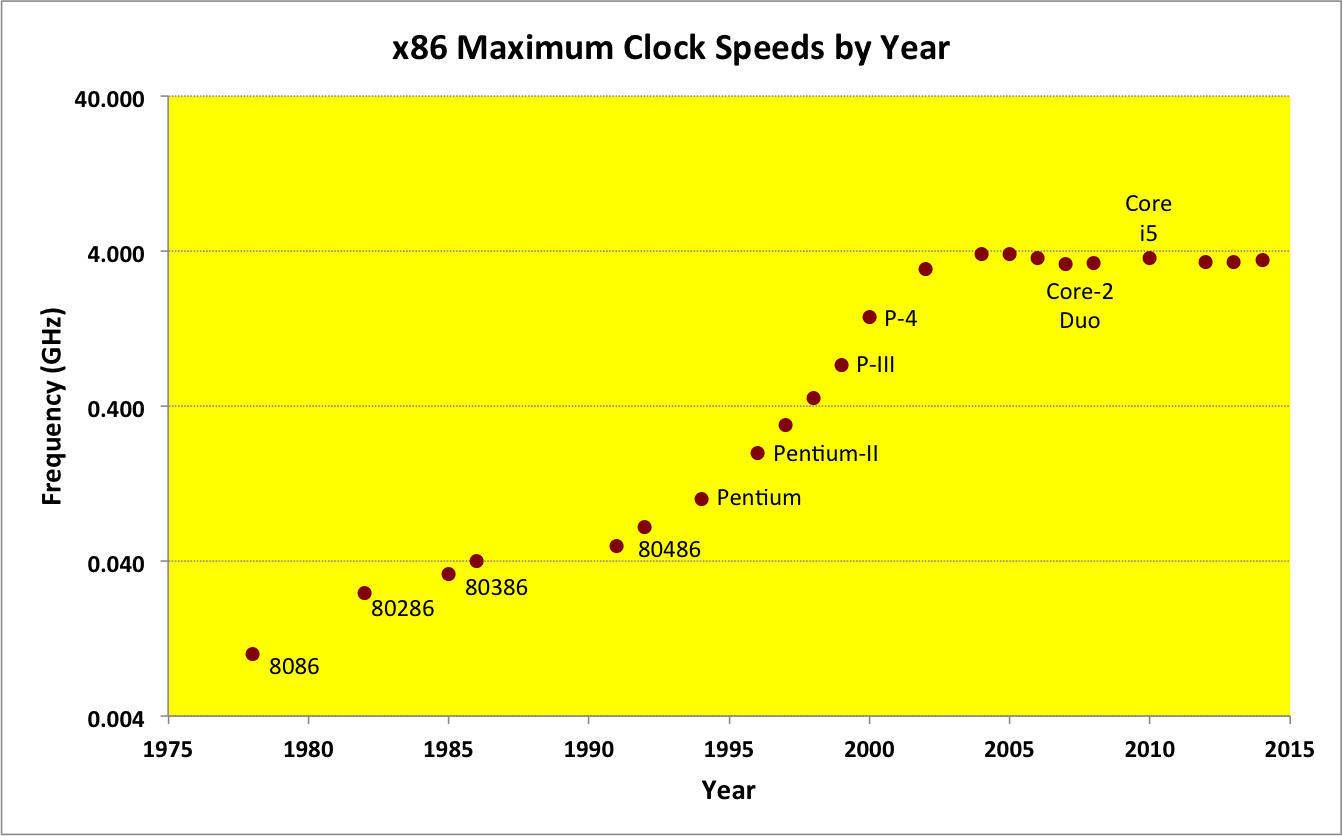
Before 2005, CPU clock speeds rose dramatically, doubling roughly every two years. The following chart shows this change in speed over 40 years:
Note that the scale on the left is a logarithmic scale, with each line being an order of magnitude increase.
Thanks to this rapid increase between 1975 and 2005, software developers and companies whose programs were sluggish and inefficient could count on faster clockspeeds in the future to make their programs perform acceptably for their users. In some circles, this time became known as the era of the free lunch for software developers, because the same software application would run twice as fast every two years, without its developers having to lift a finger.
As can be seen in the chart above, this "free lunch" era ended in 2005, when the costs of dealing with heat buildup, electron leakage, and other problems made it impractical for CPU manufacturers to keep increasing their clock speeds.
However, while clock speeds stopped increasing in 2005, Moore's Law has continued unabated: Every two years, CPU manufacturers have continued to squeeze the same amount of circuitry into half the area. In 2006, CPU manufacturers used this capability to fit two complete CPUs into the space formerly required for one, and called the results dual-core CPUs. By 2008, manufacturers could fit four CPUs into the space of one, yielding quad-core CPUs. By 2010, eight-core CPUs were available. And so on, with many-core CPUs available today:
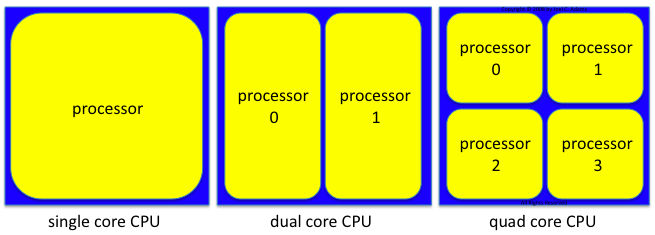
In today's multicore world, CPUs are no longer speeding up, but a CPU's total processing capability continues to increase exponentially. That is, instead of a 5 GHz CPU, you can buy a 2.5 GHz dual-core CPU, whose two cores provide 5 GHz (2 x 2.5 GHz) worth of total CPU cycles. Instead of a 10 GHz CPU, you can buy a 2.5 GHz quad-core CPU, whose four cores provides 10 GHz (4 x 2.5 GHz) worth of total CPU cycles. Instead of a 20 GHz CPU, you can by a 2.5 GHz eight-core CPU, whose eight cores provide 20 GHz (8 x 2.5 GHz) worth of total CPU cycles. And so on. The challenge is now writing software that can take advantage of the multiple cores in these new CPUs.
The exercises we have done previously have all involved writing sequential programs, meaning the program's statements are performed one after another (i.e., in a sequence). This was the logical way to write software back when a CPU had just one core, since that one core could only perform one statement at a time.
By contrast, each core of a multicore CPU can be performing a different statement at the same time. This makes it possible to write parallel programs -- programs that are divided into pieces, with each piece running on a different core. This parallel execution can provide faster execution, but only if we redesign our software to: (i) break a problem into pieces, and (ii) have each core solve a different piece of the problem. This can make designing and debugging programs more difficult, because when multiple things can happen at the same time, the program logic has to be correct regardless of which combination of statements are performed simultaneously.
This week's exercise is to speed up a time-consuming operation and explore how the parallelization works. We will start by timing the sequential version of an operation. Then we will convert that operation to a parallel version that will run faster on a multicore CPU, and time that parallel version using different numbers of cores. Finally, we will explore different ways such an operation can be "parallelized".
Unlike previous lab exercise, this week has two different options for completing the exercise, depending on whether you are taking the course in-person or remotely: