Vision and Perspectives
Seeing but Not Perceiving
Go and tell this people:
“‘Be ever hearing, but never understanding;
be ever seeing, but never perceiving.’
Make the heart of this people calloused;
make their ears dull
and close their eyes.
Otherwise they might see with their eyes,
hear with their ears,
understand with their hearts,
and turn and be healed.”(Isaiah 6:9-10, NIV)
Logistics
- Homework 3: Kaggle Competition (see description)
- Quiz 3 this Friday
- One last lab on Friday
- All late work needs to be done by end of week
Object Detection

Semantic Segmentation

Abbreviated History of Computer Vision
- 1966: “The Summer Vision Project” at MIT (Seymour Papert, Marvin Minsky, Gerald Jay Sussman, and others): identifying objects in a scene; undergrad researchers
- Many specialized approaches to specific tasks (e.g., OCR, face recognition, etc.)
- 1989: LeCun et al. use backpropagation to train a convolutional neural network (CNN) to recognize handwritten digits
- 2009: ImageNet dataset created (Fei-Fei Li), with 14 million labeled images
- 2012: AlexNet wins ImageNet competition, using CNNs to recognize objects in images
- 2021: OpenAI releases CLIP, connecting vision and language, and DALL-E, which uses it to generate images from text descriptions
The CNN Breakthrough
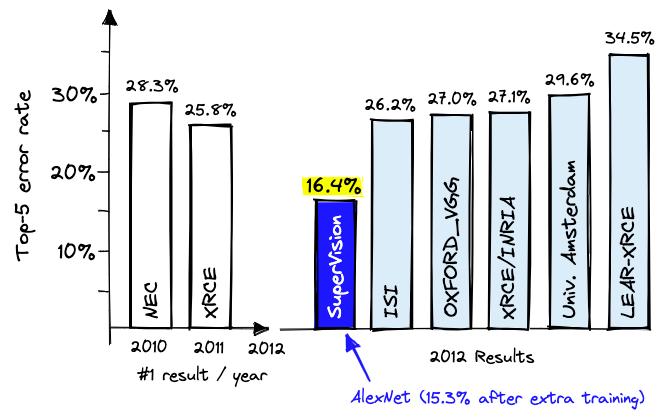
Source: Pinecone blog
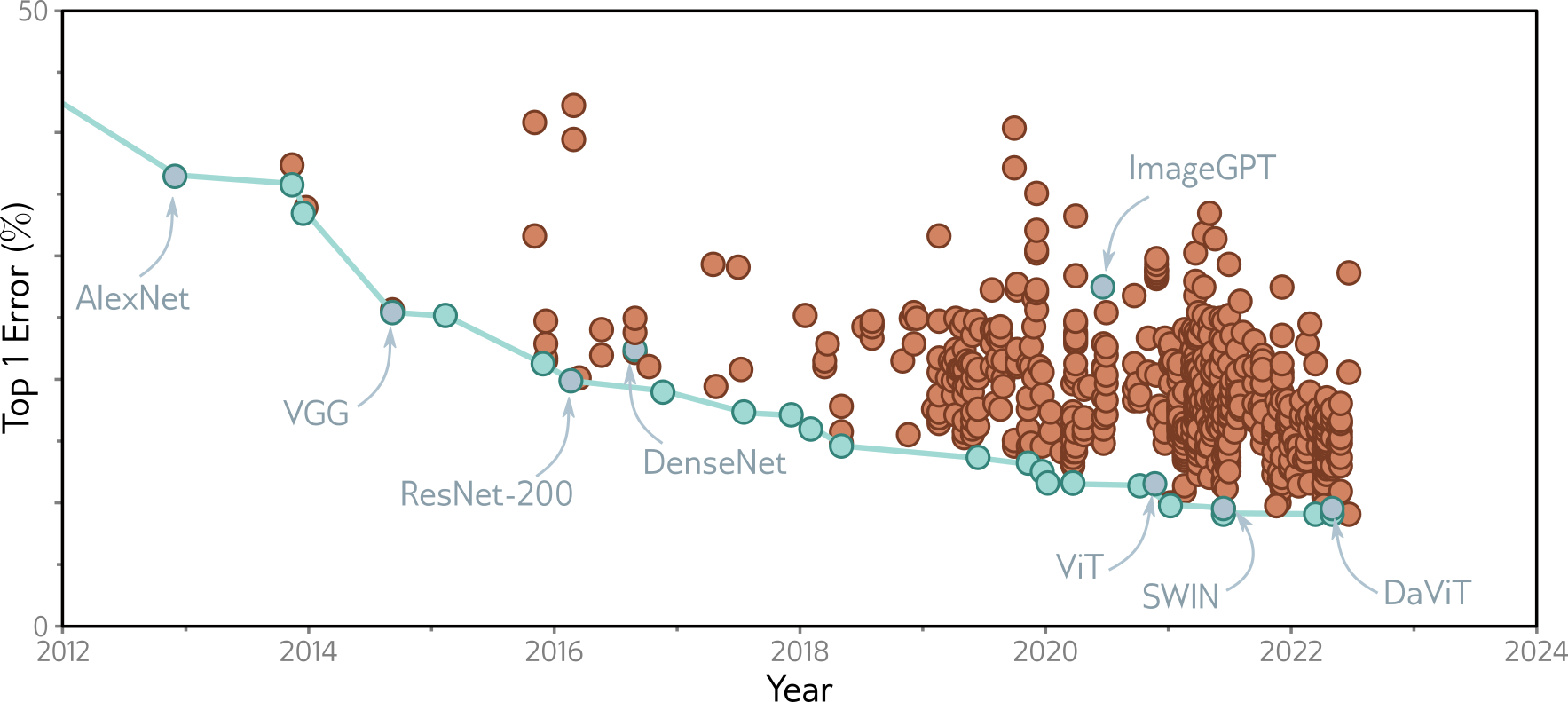
Advances Since AlexNet
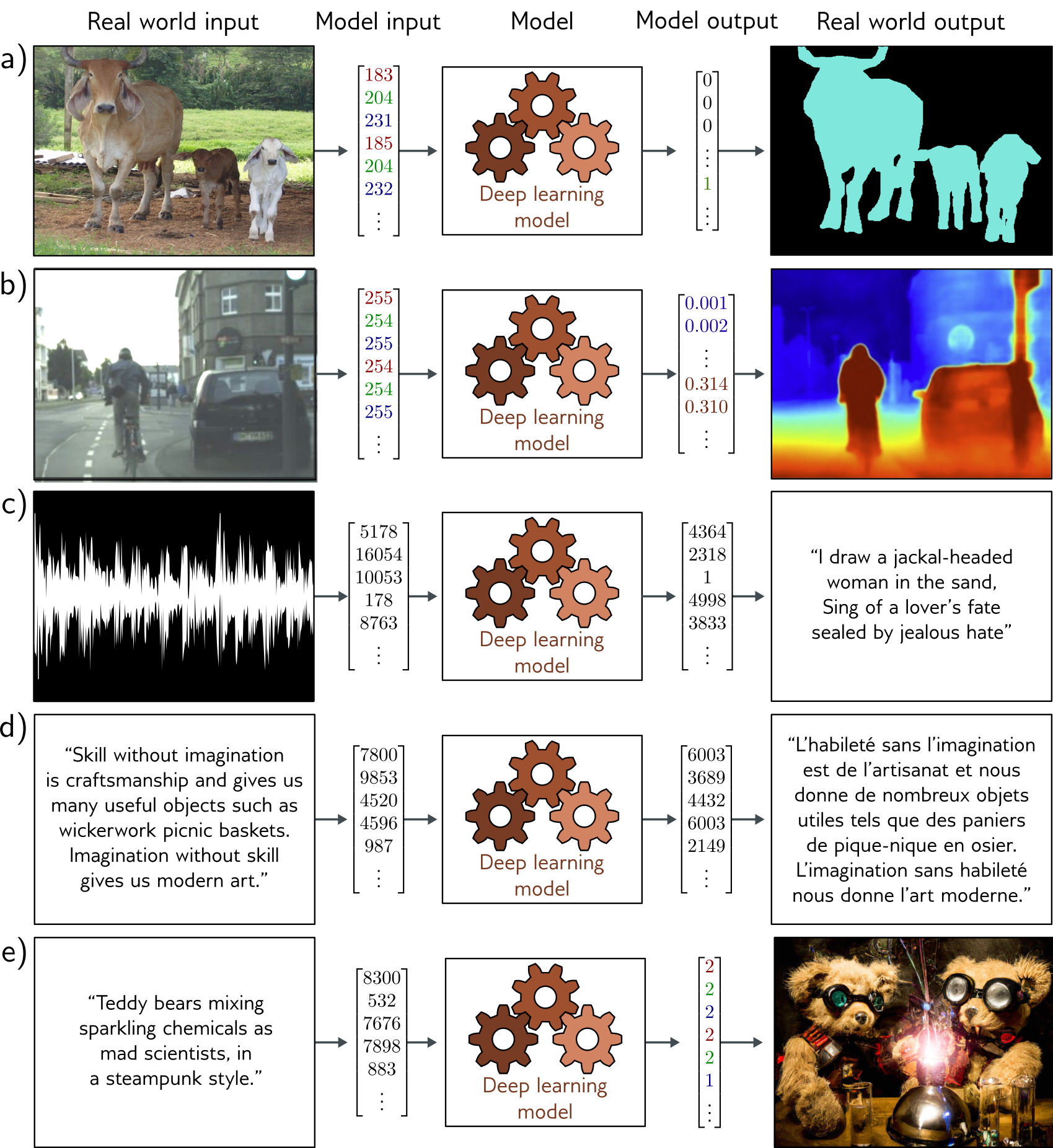
Applications of Computer Vision
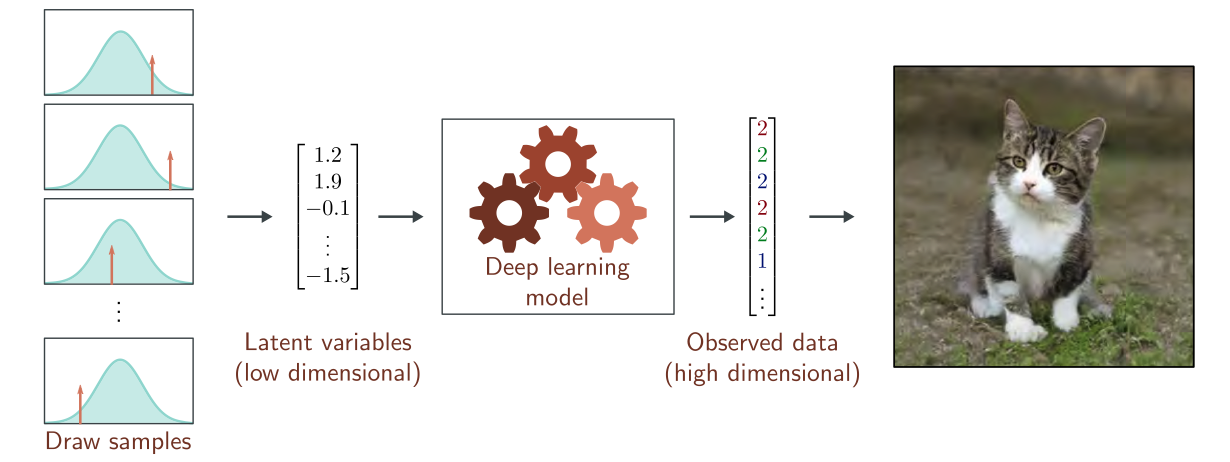

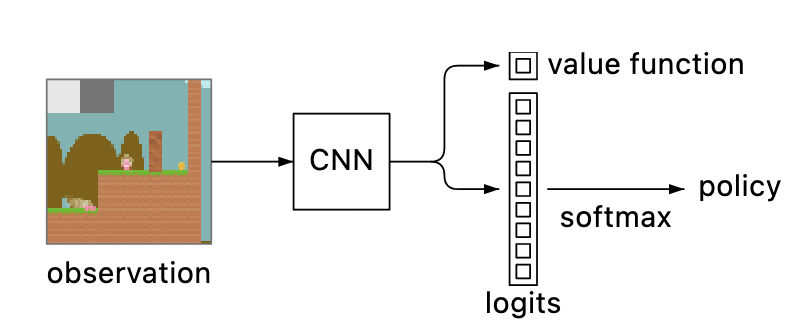
Reinforcement Learning
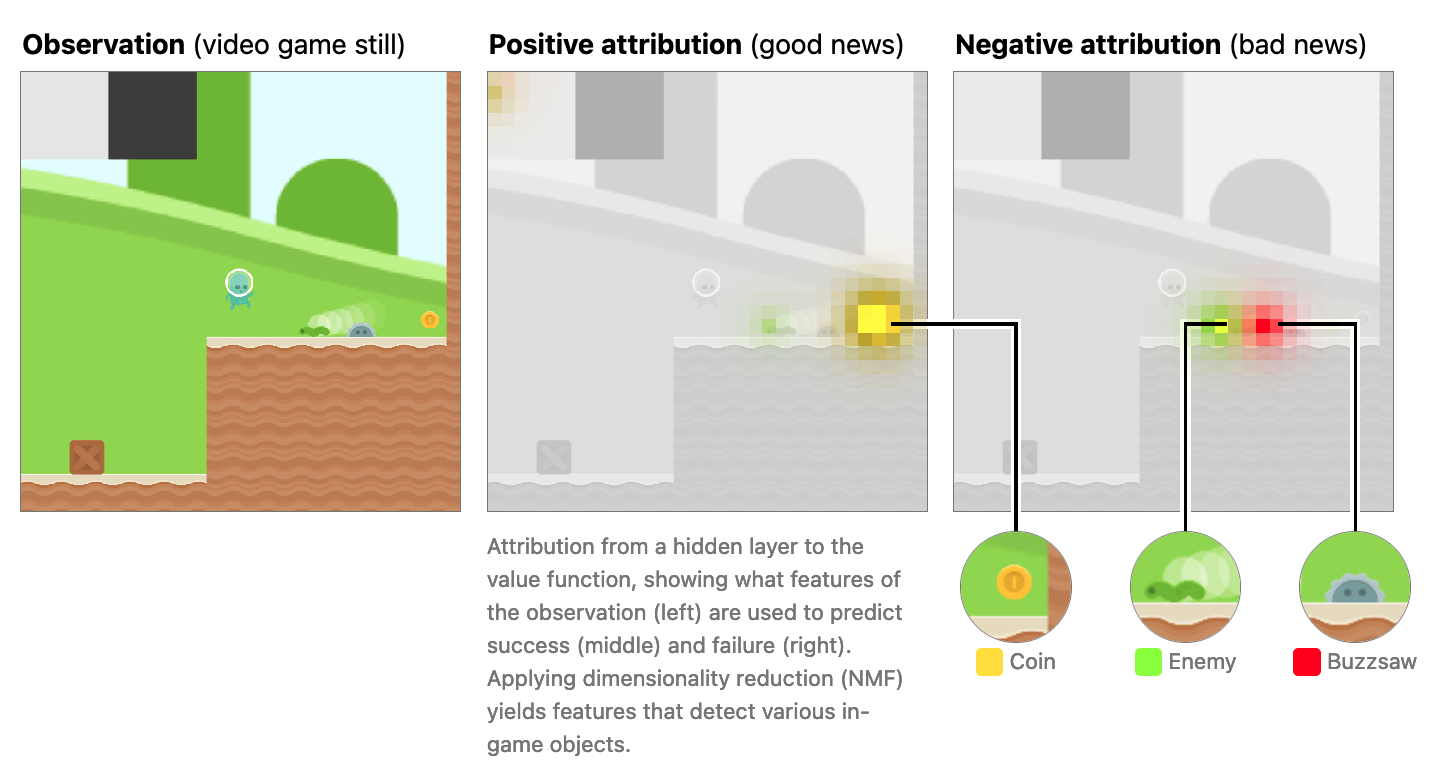
Source: Understanding RL Vision
Warmup
- Suppose a neural network computes
a,b,c, anddas outputs of some linear layers, then computesmax(a, b, c, d). Can you backpropagate through themax? Why or why not? - Our MNIST classifier took inputs of size 28x28, which we flattened to 784.
- What did the inputs look like for our (larger, color) images of flowers or pets?
- Considering a cat-vs-dog classifier: How many parameters would a logistic regression model have for these inputs?
- What could you do to make the classifier recognize dog fur, no matter where it is in the image?
Architectures
ML researchers have been very creative!
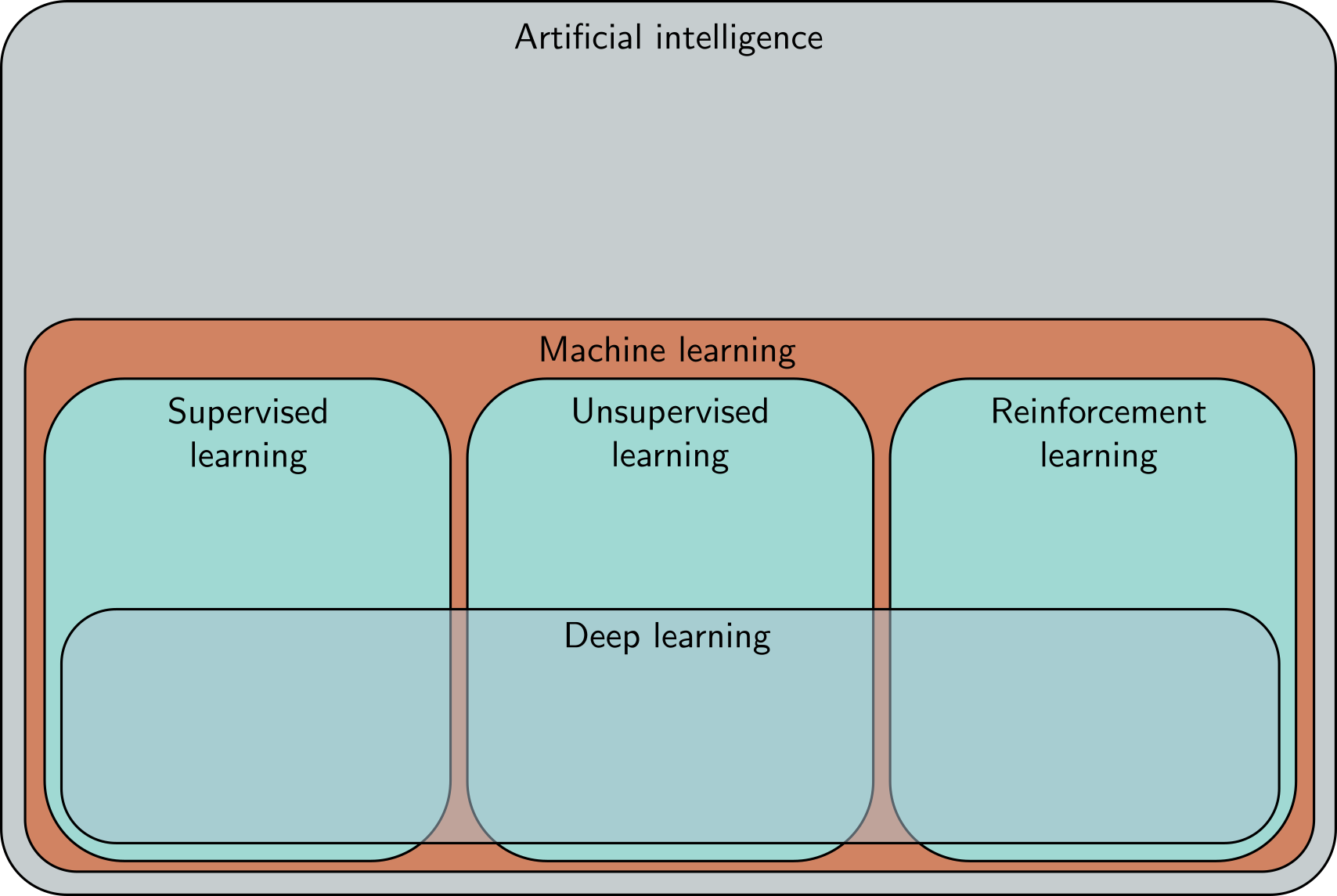
- CNNs: Convolutional Neural Networks combine:
- Convolution layers
- Pooling layers
- Fully connected (Dense / Linear) layers
- Vision Transformers (ViT)
- U-Nets
- Variant of CNN where output is same size as input
- Used for image segmentation
- Generative Adversarial Networks (GANs), Autoencoders, etc.
CNN Explainer
https://poloclub.github.io/cnn-explainer/
Activity:
- Select the red pepper image on the top (4th from the left).
- Notice that the output probability is high for “bell pepper”, but also gives some probability (how much?) to “orange”. Click on the “orange” label.
- Trace backwards through the network: where did those probabilities come from?
- The output layer looks like our MNIST classifier’s output layer: can you find the linear projection and softmax?
- Click the Max Pooling layer to understand how it gets a 13x13 image from a 26x26 image.
- Click the Convolutional layer to understand how it gets a 26x26 image from a 28x28 image.
Acknowledgements
Some figures from Understanding Deep Learning, by Simon J.D. Prince, used with permission
Wednesday
Bringing it all together
In your notes, write a one-sentence response to each of these questions by using specific concepts that we’ve learned in class. Share your responses with table-mates.
- Where does the intelligence in a neural network come from, and how does it get there?
- Does a neural network learn from its mistakes? When? How?
- Why does training a big model like ChatGPT need so much energy and computation? (Where does it all go?)
- Are AI systems more or less objective than humans? Explain.
If you finish early: draw a diagram of what a batch of input to an image classifier looks like.
Homework 3 Errata
- Data loader was shuffling images, so indices were inconsistent. See assignment for fix.
- See assignment for tips on how to implement data augmentation in Keras
Input Looks Like
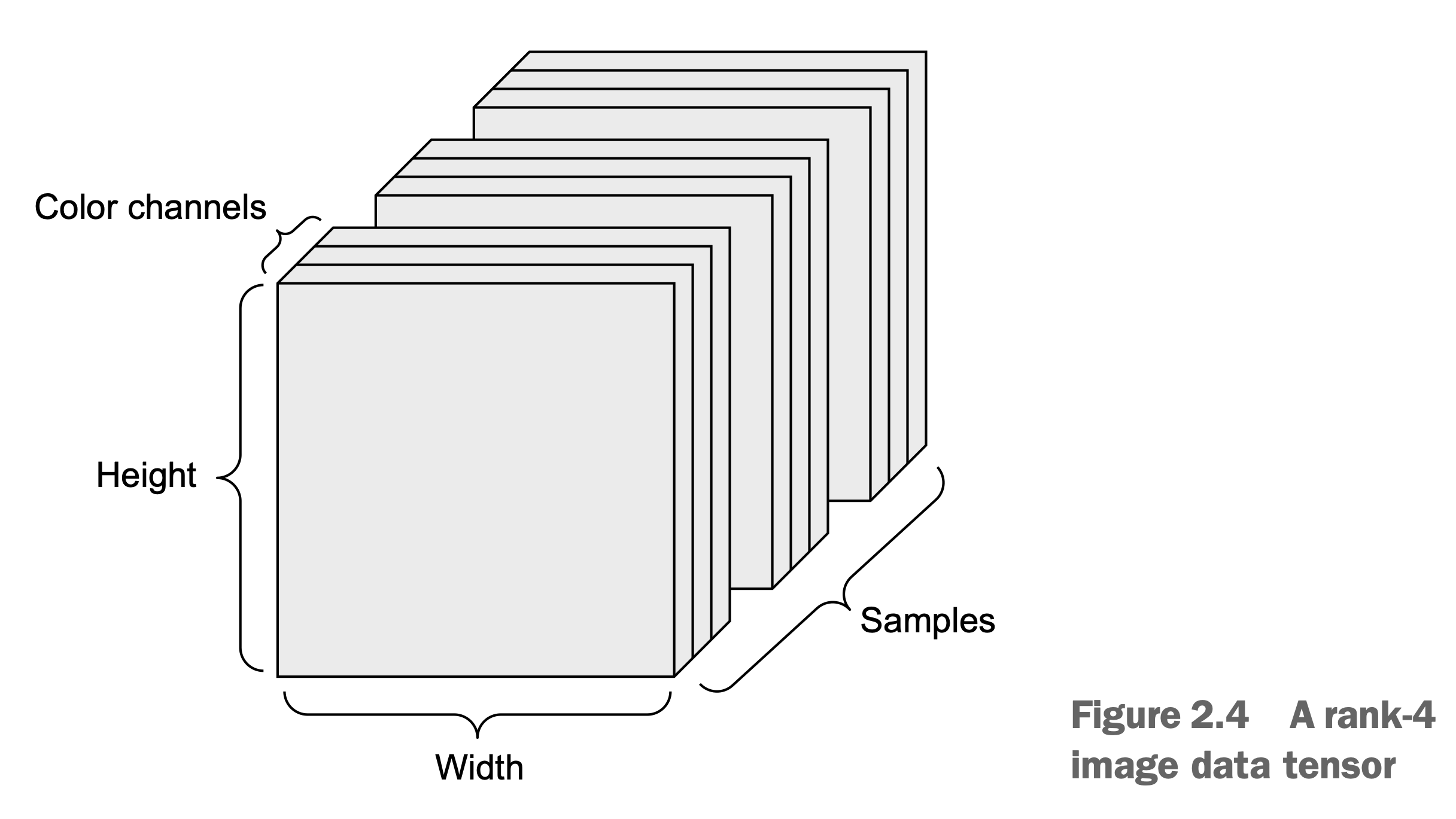
Batches
Why: Often more efficient to process several items at once; gradients less noisy. (But some noise in gradients is useful to avoid sharp minima, which don’t generalize well.)
How:
- Each image (or text document, or sound, or …) needs to be the same size
- Limited by GPU memory (especially for the backward pass)
Convolution Layers
Two big improvements over fully-connected layers:
- Parameter sharing: each filter is used at every position in the input, so we only need to learn one set of weights for the filter.
- Translation invariance: the same filter is used at every position, so the network can recognize the same feature no matter where it is in the image.
What Convolution Does
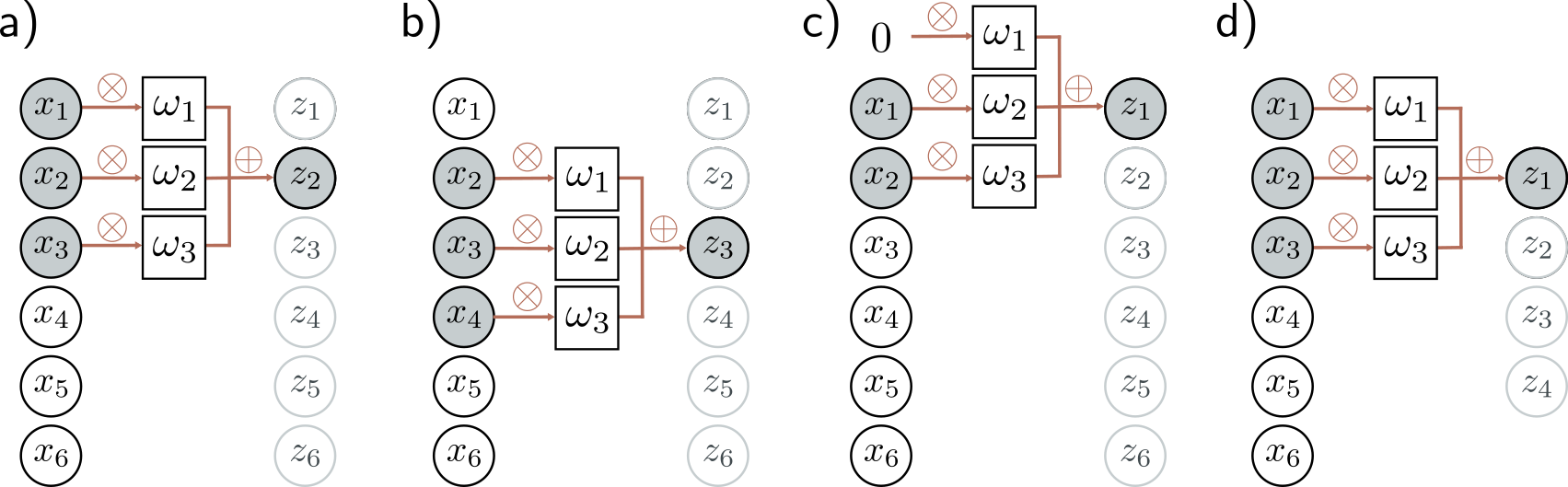
Anatomy of a Convolutional Layer
- A tiny linear layer (e.g., 3x3)
- … that is applied at every (valid) position in the input
Example: Conv2D(filters=16, kernel_size=(3, 3), input_shape=(32, 32, 3))
- Input: (height, width, input_channels)
- Weight (kernel) shape: (3, 3, input_channels, output_channels)
- Output: (height - 2, width - 2, output_channels)
Pooling Layers
- Reduce the size of the input
- Enables each pixel to represent a larger area of the input
Putting it together: VGG
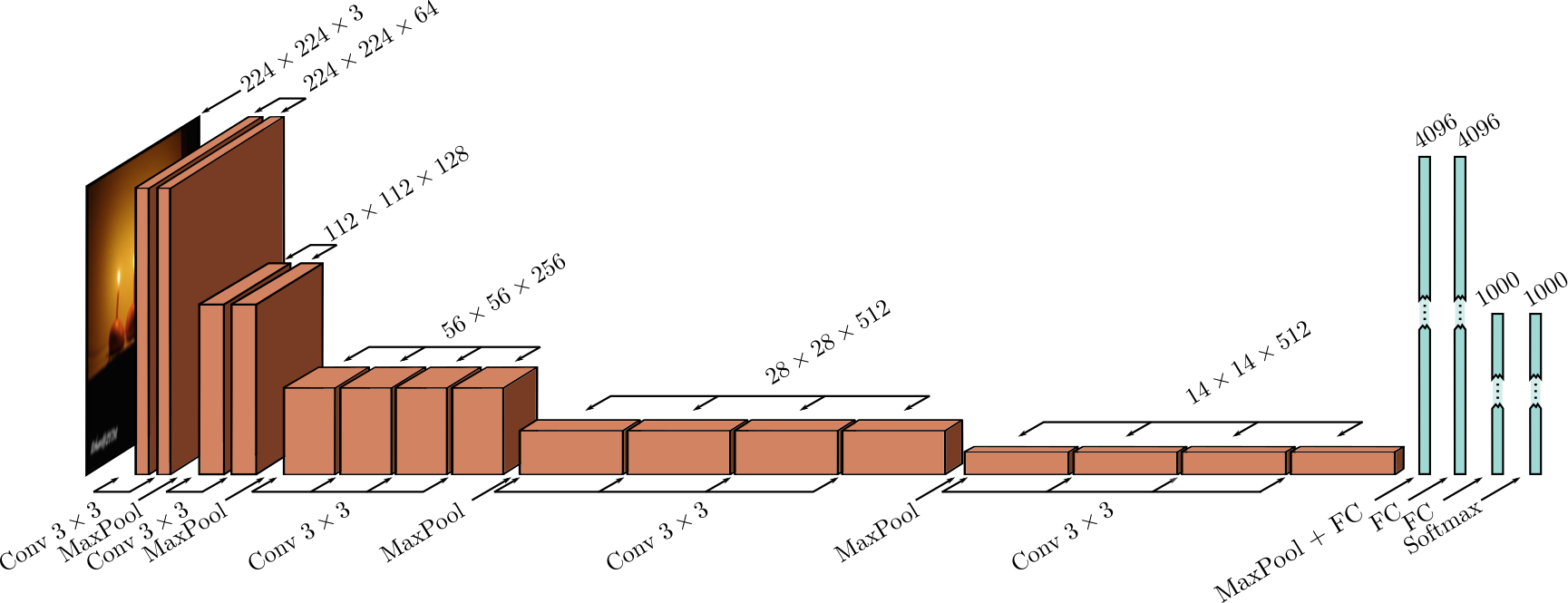
Simonyan, 2016, Very Deep Convolutional Networks for Large-Scale Image Recognition
Transfer Learning
- Most early layers learn features that are useful for many tasks
- Later layers learn features that are specific to the task
- Transfer learning: Pre-train on a large dataset, then reuse most of the model for a new task
- If task has same structure: fine-tune
- If output shape or task is different: reuse body as feature extractor, then train new head
Ethical and Social Issues
Can AI be conscious?
- Is it possible in principle?
- Are any current systems conscious?
- If an AI were conscious, how could we tell?
- Is it possible to create a conscious AI (perhaps unintentionally)?
Some Perspectives
- Turing Test: if a system can deceive people into thinking it’s human, it’s intelligent
- Chinese Room (Searle): a system can appear to understand without actually understanding
- Indicator properties of consciousness: global workspace, higher-order theories, agency and embodiment (Butlin et al, 2023)
Indicator Properties of Consciousness
- Global Workspace: specialized subsystems integrated into a coherent whole; selective “attention” to relevant information
- Higher-Order Theories: distinguishing reliable from unreliable perceptions
- Agency and Embodiment: learning from feedback, selecting actions to pursue goals, modeling how the world responds
Butlin et al. 2023 Consciousness in Artificial Intelligence argues that (1) no current AI system is conscious but we could build one that at least satisfies these indicators.
Aside: Large Language Models
- Learn statistical patterns in language: after “The capital of France is”, likely word is “Paris” (“Stochastic Parrots”)
- Doesn’t mean that the model “knows” that Paris is the capital of France
- Counterexample: “Twinkle twinkle” is followed by “little”, but model doesn’t “know” that “Twinke twinkle little”
- See more: Talking about Large Language Models | February 2024 | Communications of the ACM (and CS 376)
Practical AI Ethics
- AI needs data (privacy)
- …and empowers organizations that aggregate data
- AI needs lots of computation
- AI’s outputs affect people
- predictions and decisions (bias, discrimination, gig labor, …)
- how we perceive each other (and ourselves)
- how we perceive ideas (misinformation)
- AI does things that people once did
- AI systems can be attacked in new ways
- AI embeds values about what is human
- AI tells us about our own intelligence
Hypothetical Example: Shoplifting Prediction System
- Problem: busy store, too many cameras to monitor
- Input: surveillance camera video
- Output: people, labeled by likelihood to shoplift
What issues might come up?
- bias
- transparency / explainability
Hypothetical Example: Resume Screening
- Problem: many candidates, many jobs
- Input: resumes, job description
- Output: ranked list of most promising matches
What issues might come up?
- bias
- feedback loops
Hypothetical Example: News Recommendation
- Problem: too much going on (information overload)
- Input: articles
- Output: ranked list of articles for me to read
What issues might come up?
- feedback loops
- measurement bias
- potential for adversarial manipulation
Hypothetical Example: Popularity Prediction
- Problem: past ad campaigns fell flat.
- Input: image to be used in social media marketing
- Output: predicted level of engagement (likes, shares, comments)
What issues might come up?
- measurement bias
- stereotyping
- clickbait
A few questions to ask about ML
- General
- Is our data representative? (vs, e.g., feedback loops)
- Were stakeholders involved in the design?
- How vulnerable is the system to attack?
- Performance
- Robust? Reliable?
- Testable
- Clarity
- Are results accurate in real-world?
- Are system’s biases understood and reported?
- Is there recourse if the system is wrong?
- Can decisions be explained?
Source: Shneiderman, Human-Centered AI, pp 246-247
Why transparency?
Did this classifier successfully learn to recognize a “dumbbell”?

Source: Google Blog
Closing
Coming up in CS 376
- Generative models
- Sequence data (e.g., text) and models (Transformer, etc.)
- Diffusion models
- A bit on:
- Reinforcement learning
- Interpretability
- Designing AI-powered interactive systems
Things we didn’t get to
- Lots of details about how deep learning works (optimizers, initialization, etc.)
- Neuro-symbolic AI
- Many, many applications
- Lots of ethical and social issues
Closing Up
- Quiz 3 on Friday
- Homework 3 and Lab 7 due Saturday
- No final project (but start thinking about final project for CS 376!)