Learning Recap and Avoiding Overfitting
Review Quiz
- Suppose a classifier outputs a score (logit) of 0 for every class. Compute the probabilities:
- if there are 2 possible classes?
- if there are 256 possible classes?
- what is the cross-entropy loss (in bits)?
- Suppose that there are 2 possible classes, and again the classifier outputs 0 and 0. The correct answer for a certain example is class A.
- What happens to the cross-entropy when we increase the score of class A by 1?
- What if we instead decrease the score of class B by 1?
- (First give a back-of-the-envelope estimate. Then, compute the actual cross-entropies.)
This week’s Objectives
- Explain how a pre-trained model can be repurposed for a new task by separating it into a general-purpose “body” (aka “encoder”) and a task-specific “head”.
- Identify some examples of data augmentation and regularization.
- Predict the effect of data augmentation and regularization on model training.
- Implement a multi-layer neural network using basic numerical computing primitives
Clarification: Regression
- Predict a continuous value, vs a category
- Describes the result, not the method
- Method: Not necessarily a linear function!
- Decision trees (“CART” algorithm = “Classification and Regression Trees”)
- Random forests
- Neural networks
Fine-Tuning: Head and Body
Linear regression and logistic classification are the final layers of models.
Logistic Classification: Two variations
- “Pick the best answer”: one big softmax
- “Choose all that apply”: a softmax (really a sigmoid) for each class
What’s the difference between the two?
- For a “yes”/“no” question, they’re equivalent.
- Pick the best: zero-sum. Increasing probability of one class decreases probability of all others.
- Choose all that apply: each class is chosen independently.
- Which to choose: match your situation. Rarely makes a big difference.
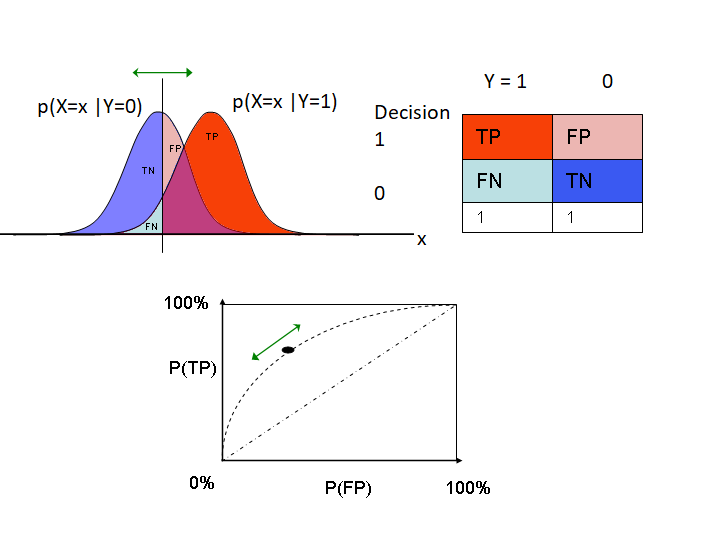
Thresholds
At what probability do you decide that a class is present?
- Medical alarm example: may want to signal a potential problem even if uncertain
- Trade-off between false positives and false negatives
- Applies to both “pick the best” and “choose all that apply”
- Can be different for each class
Wednesday
If anyone uncovers a pit or digs one and fails to cover it and an ox or a donkey falls into it, the one who opened the pit must pay the owner for the loss and take the dead animal in exchange.
If anyone’s bull injures someone else’s bull and it dies, the two parties are to sell the live one and divide both the money and the dead animal equally. However, if it was known that the bull had the habit of goring, yet the owner did not keep it penned up, the owner must pay, animal for animal, and take the dead animal in exchange.
Exodus 21:33-36 (NIV)
Review
Which of the following is a regression in the sense we’ve been using? (A) logistic regression, (B) a decision tree predicting a number, (C) finding the slope of the line tangent to the loss function, (D) taking the average of the log of a probability
When you fine-tune a model, you can (A) replace the “body”, (B) replace the “head”.
T/F: you need to set a decision threshold before training a model.
Changing the decision threshold affects (A) training loss, (B) validation loss, (C) false positive rate, (D) the dimensionality of the last linear layer.
Suppose the input to the last linear layer is a 512-dimensional vector. Describe the shape of the weight matrix and output vector for (1) predicting the vertical position of the nose in a face, (2) labeling an image as blurry vs focused, and (3) labeling an image as A, B, or C.
Logistics
- Exams-by-us first milestone: write one draft question by Monday.
Backpropagation
How much does a change in each input affect the output?
Consider plotting the loss as a function of each parameter. What’s the slope of that plot at the current value?
The Backpropagation Trick
- Start with the simplest gradient to compute.
- Work backwards one step at a time.
Example: Linear Regression with MSE
Notation: x_grad means “the gradient of the loss with respect to x”, or \(\frac{\partial L}{\partial x}\).
- What’s
resid_grad? (the gradient of the loss with respect to the residuals) - What’s
b_grad? (the gradient of the loss with respect to the intercept) - Chain rule: \(\frac{\partial L}{\partial b} = \frac{\partial L}{\partial resid} \frac{\partial resid}{\partial b}\)
- Key idea:
resid_gradis already computed! - All we need to calculate is \(\frac{\partial resid}{\partial b}\)
Overfitting
Suppose you carefully study past exams.
When the question includes the letter “m”, the answer is always “B”.
- Can you get low loss on the practice exam?
- Will you do well on the real exam?
Overfitting
- Learning the real relationship between inputs and outputs is harder than learning a shortcut.
- Goodhart’s Law: “When a measure becomes a target, it ceases to be a good measure.”
Label Smoothing Penalizes Overconfidence
Regularization inside a model
- Weight decay (penalize large weights)
- Dropout (randomly zero out activations)